Evaluating Evolving Agent Systems at Scale with Frontier-CS
Evolving agent systems are advancing fast, but evaluation hasn't kept up. We show how Frontier-CS enables comprehensive, large-scale benchmarking of evolving agents—moving beyond small case studies to fair comparison at scale.
Evolving Agents Are the Next Frontier for LLMs
Evolving agent systems—including methods based on continual learning, memory evolution, and context refinement—are emerging as a promising path toward agents that improve through experience rather than relying on a fixed policy. This matters especially in discovery-style settings, where the agent must learn from prior failures, accumulate useful knowledge, and adapt its future behavior over long horizons. Recent work such as GEPA and ACE (Agentic Context Evolution) reflects this trend.
A Promising Direction, Bottlenecked by Evaluation
However, evaluation has not kept up. Most prior work demonstrates gains on only ~10 tasks, often selected case studies or small benchmark subsets. That is a weak test for evolving systems: improvement on three or four tasks does not tell us whether a method can generalize across a broad task distribution, remain stable over many iterations, or handle the kinds of long-horizon, high-difficulty reasoning that make evolution necessary in the first place.
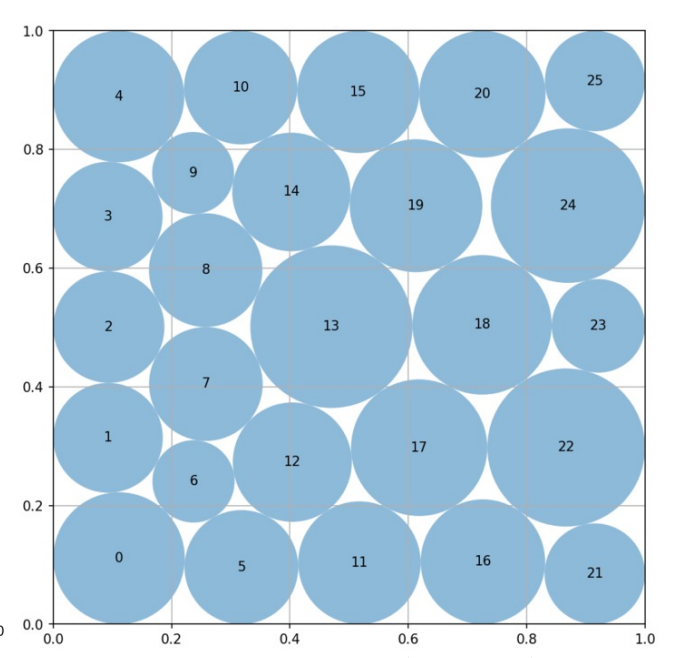
Worse still, many tasks used in prior evolving-agent papers are not expert-crafted and saturate far too quickly. As a result, they fail to measure continued progress in the domain. Circle packing is a telling example: ThetaEvolve, TTT-Discover, AdaEvolve, and EvoX all converge to essentially the same value, 2.635983. Once multiple methods collapse to the same endpoint, the benchmark no longer measures open-ended improvement—it only measures how fast a system reaches saturation.
Why the Evaluation Gap?
We identify two core failure reasons. First, many existing tasks are community-contributed and community-maintained, resulting in limited scale and inconsistent quality. Second, many of these tasks do not have enough difficulty or headroom to meaningfully measure continued progress. Their search spaces are often too small.
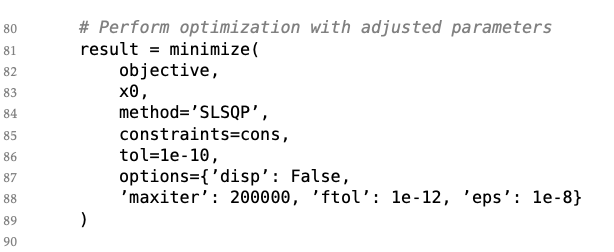
Circle packing is a representative case: the core solution is typically just a ~100-line Python program, and most methods differ only in how they wrap existing SLSQP-based optimization routines.
cons).Frontier-CS as the Standard Benchmark for Evolving Agents
Frontier-CS is built to solve exactly the failures of current evaluation. It includes 172 algorithmic tasks and 68 research tasks, all expert-designed by ICPC World Finalists and CS PhDs. That gives it both the scale and the quality consistency missing from small, community-maintained benchmark sets.
Each Frontier-CS task is a distinct, open-ended problem with its own environment, yet still admits deterministic scoring. As a result, Frontier-CS can evaluate evolving agents comprehensively, at scale, and on tasks that are difficult enough to meaningfully measure continued progress.
Permutation is a good example of the kind of task Frontier-CS is built around. In this interactive problem, the agent must recover a hidden permutation of length
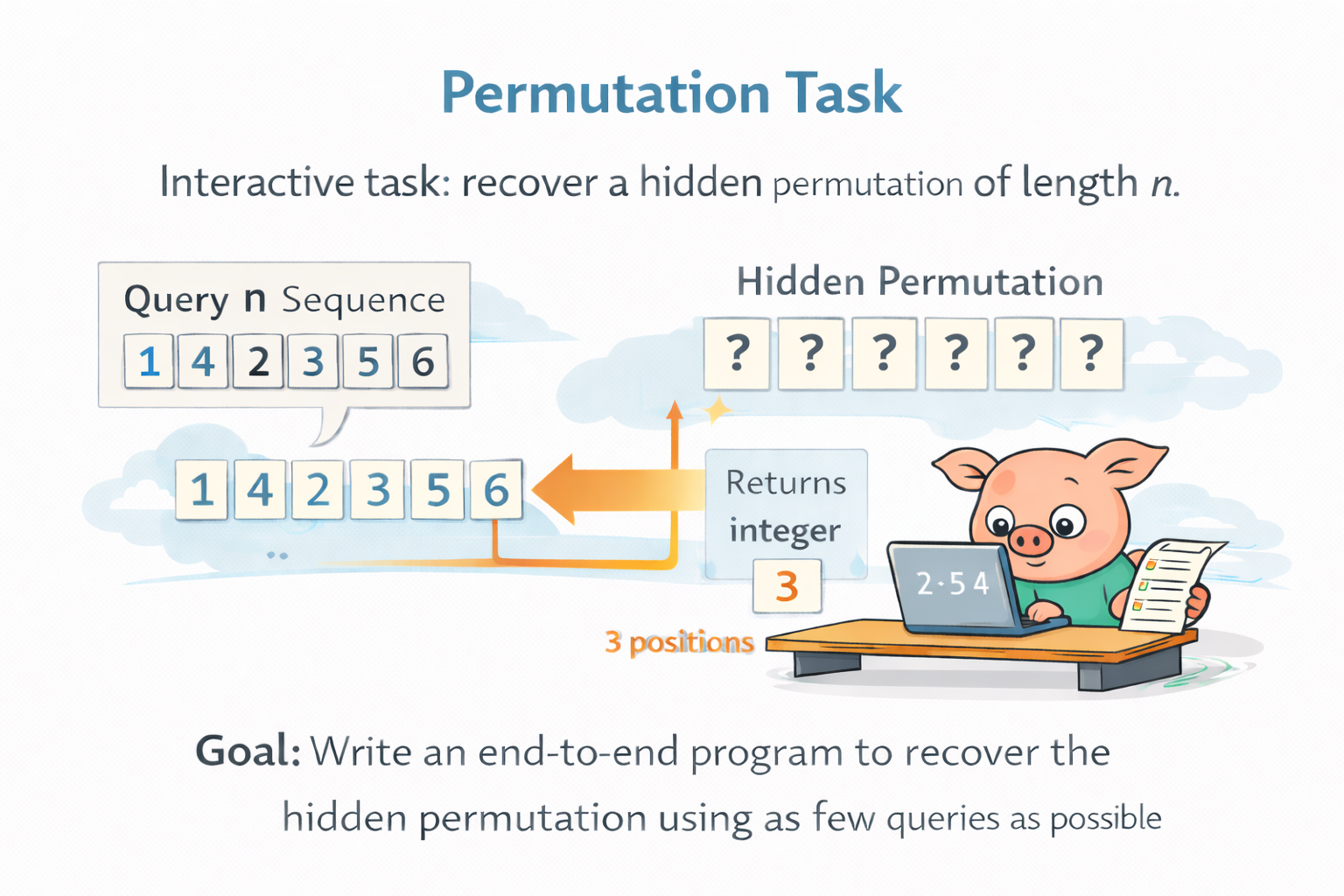
What makes this task valuable is not just its combinatorial scale, but the form of interaction itself. The agent has substantial freedom in what to ask, what information to extract from each response, and how to adapt future queries based on past feedback. In other words, the task creates real room for strategy design, information-efficient exploration, and long-horizon reasoning. This is very different from tasks like circle packing, where the search often collapses quickly into a fairly standard optimization problem with limited room for fundamentally different solution strategies. At the same time, Permutation still admits deterministic scoring through query count, enabling clean and scalable comparison across methods.
From Small Case Studies to Comprehensive Evaluation
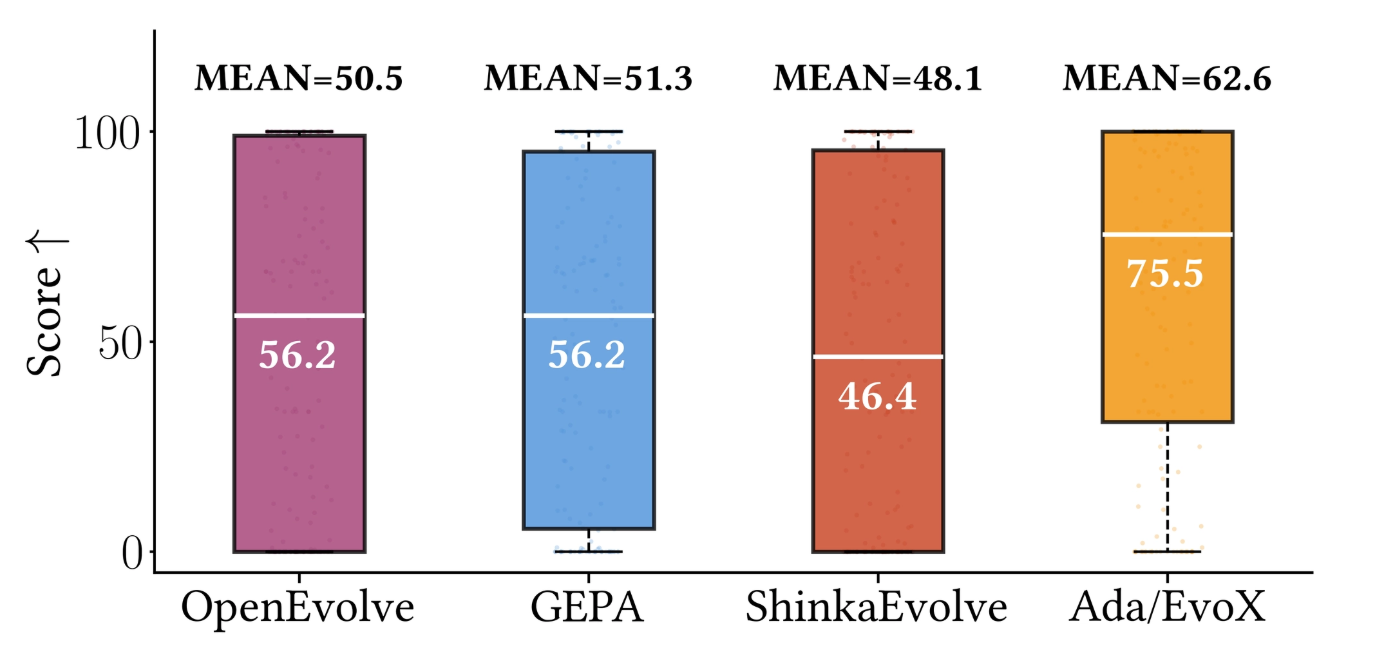
Frontier-CS is already helping push the field toward real large-scale evaluation. SkyDiscover uses it in a 200+ task benchmark suite, including 172 Frontier-CS programming problems, to compare methods under the same framework, models, and budgets. That is a sharp contrast to earlier evaluations built around only a small handful of tasks. With Frontier-CS, evolving-agent systems can finally be compared comprehensively, fairly, and at scale.