Learning a Continual Learning AI Researcher on Frontier CS
What if AI could research how to improve itself from every experiment it ever ran? We use ALMA to automatically learn continual learning AI researchers on Frontier CS to explore this problem.
AI Researcher should Continually Learn from Past Research Experience
Foundation Models (FMs) have allowed the formation of AI researchers for automatic scientific exploration. However, the stateless nature of the FMs challenges AI researchers to continually learn during exploration, causing them to repeatedly reflect, ideate and implement new experiments only based on idea and result from current iteration. Memory addresses this limitation by allowing AI researchers to continually learn from previous experience to better reflect, ideate and implement experiment in the future.
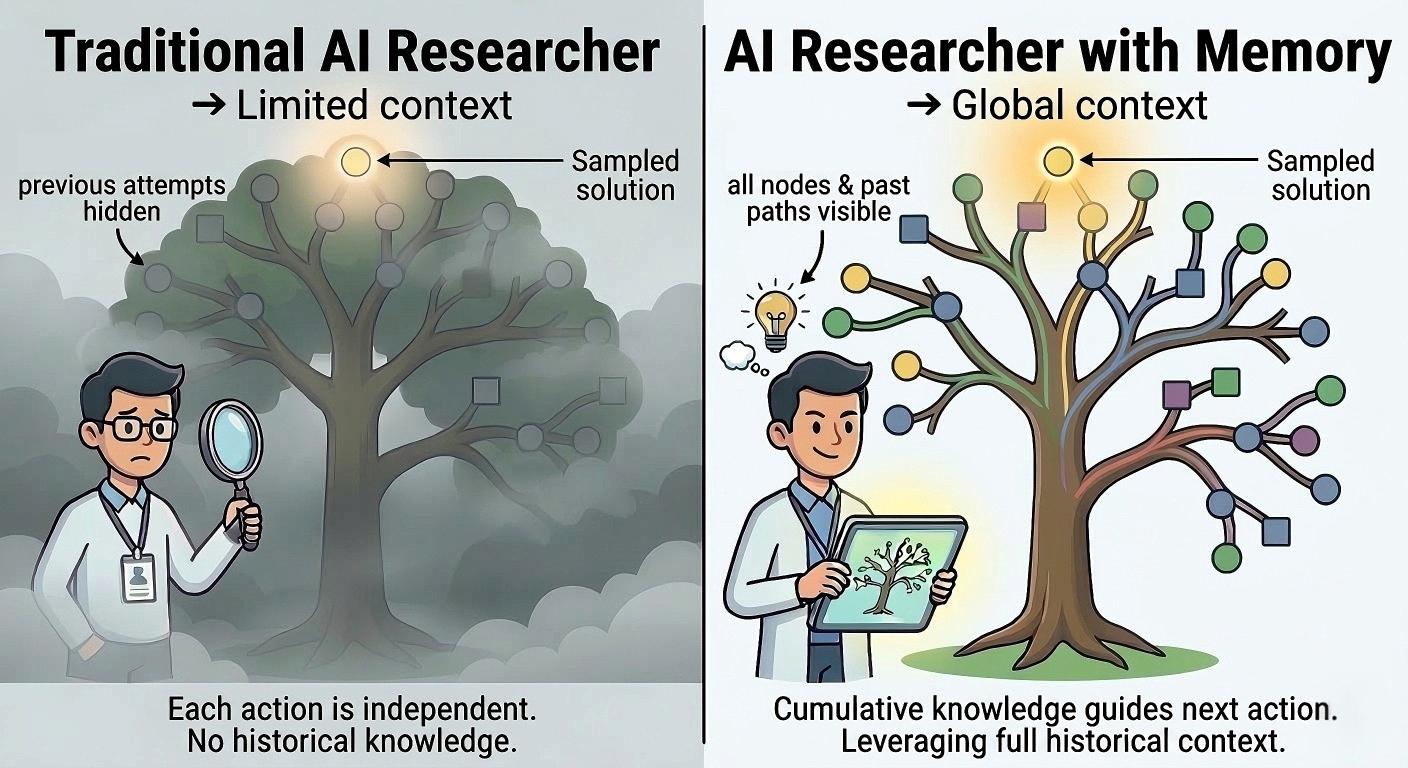
Importance of Automated Memory Design
Most automatic scientific research agentic systems do not have memory. Others utilize the predefined memory design, manually determining how memories are represented, stored, retrieved and updated. However, different research domains and objectives often require distinct memory designs to effectively leverage past experience. For example, optimizing a single research problem in chemistry, biology, or computer science may require memory designs tailored to the domain, while memory designs that support transferring general knowledge across research problems are fundamentally different. Therefore, manually designing memory structures for different domains and objectives is difficult and labor-intensive.
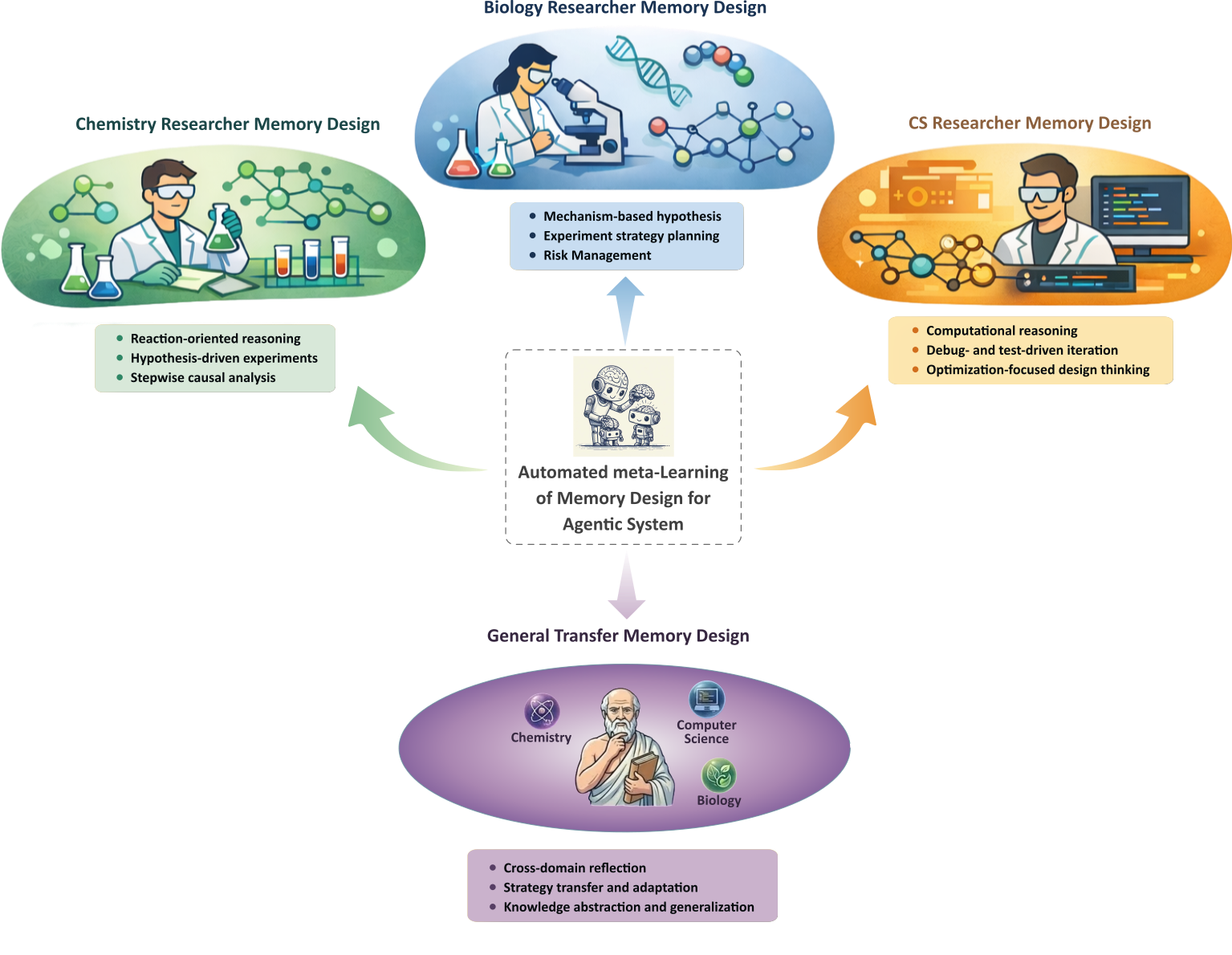
Building on these insights, we implement Automated meta-Learning of Memory Designs for Agentic systems (ALMA) on Frontier CS. We find that different optimization objectives lead ALMA to discover substantially different memory designs. When optimized for a single problem, ALMA discovers highly specialized memory designs tailored to that task, whereas optimizing for knowledge transfer across research problems yields markedly general designs.
What is ALMA?
ALMA (Automated meta-Learning of Memory Designs for Agentic systems) is a framework that meta-learns memory designs to replace hand-engineered memory designs, therefore minimizing human effort and enabling agentic systems to be continual learners across diverse domains. ALMA employs a Meta Agent that searches over memory designs expressed as executable code in an open-ended manner, theoretically allowing the discovery of arbitrary memory designs, including database schemas as well as their retrieval and update mechanisms.
Running ALMA on Frontier CS
We evaluate ALMA on the Frontier CS Algorithmic problem set, using two complementary settings:
-
Single-problem optimization — We apply ALMA to each optimization problem individually to evaluate whether the learned memory designs help the solver reuse experience from previous attempts to propose improved solutions, enabling deeper exploration of that problem.
-
Sequential problem solving — We run ALMA in a sequential problem-solving setting to investigate whether the learned memory designs allow the solver to transfer knowledge from previously seen problems to new, unseen ones.
These two settings test orthogonal capabilities: within-problem depth vs. cross-problem generalization.
Setting 1: Single-Problem Optimization
We apply ALMA to Polyominoes Packing. Polyominoes Packing is an algorithmic optimization problem that aims to maximize the packing density within a fixed area by placing as many given polyomino pieces as possible. As an open-ended optimization problem without a single ground-truth solution, it provides a suitable testbed for evaluating a solver’s ability to explore and discover effective strategies.
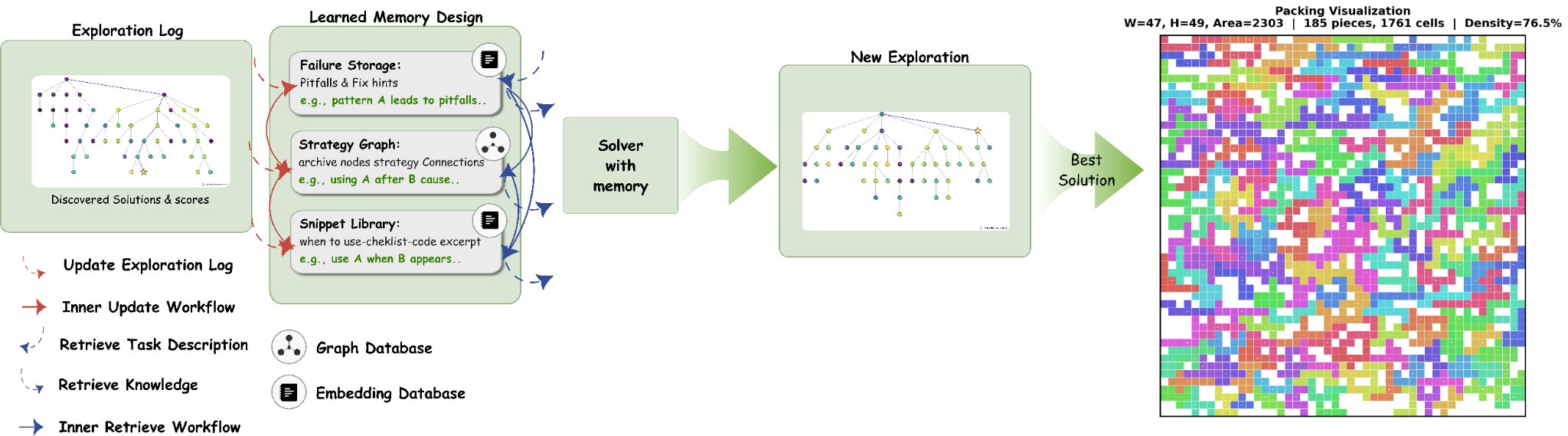
With the best learned memory design, using GPT-5-mini/medium as the foundation model, the solver achieves:
- Average packing density: 76.43% (vs. 70.13% without memory)
- Maximum density: 82.01% on test instances
This +6.3 percentage point improvement over the no-memory baseline shows that ALMA can learn memory designs that effectively guide the solver toward higher-density solutions.
The learned memory design captures common pitfalls, particularly strategies that consistently lead to low packing density. It also maintains a strategy graph that organizes previously explored strategies according to exploration order. Strategies are then stored in a snippet library alongside their corresponding code snippets, giving the solver structured access to its own research history.
Use Case 2: Sequential Knowledge Transfer
To study whether the learned memory designs enable the solver to transfer knowledge from previously solved problems to unseen ones, we run ALMA sequentially on 10 training problems, solving each only once. The solver can reuse experience from earlier problems when solving later ones. We then evaluate the learned memory design on the remaining 162 problems under the same sequential setting.
With GPT-5-think/high as the foundation model, the solver achieves a score@1 of 27.27, outperforming a solver without memory by 7 percentage points under the same model.
Comparing the learned memory designs for sequential problem solving and for Polyominoes Packing, we find distinct task domains results to different focuses of memory designs.
| Setting | Memory Design Focus |
|---|---|
| Polyominoes Packing (single-problem) | Detailed patterns, strategies, code snippets for that task |
| Sequential problem solving (transfer) | Cross-problem connections, abstract concepts, causal relationships |
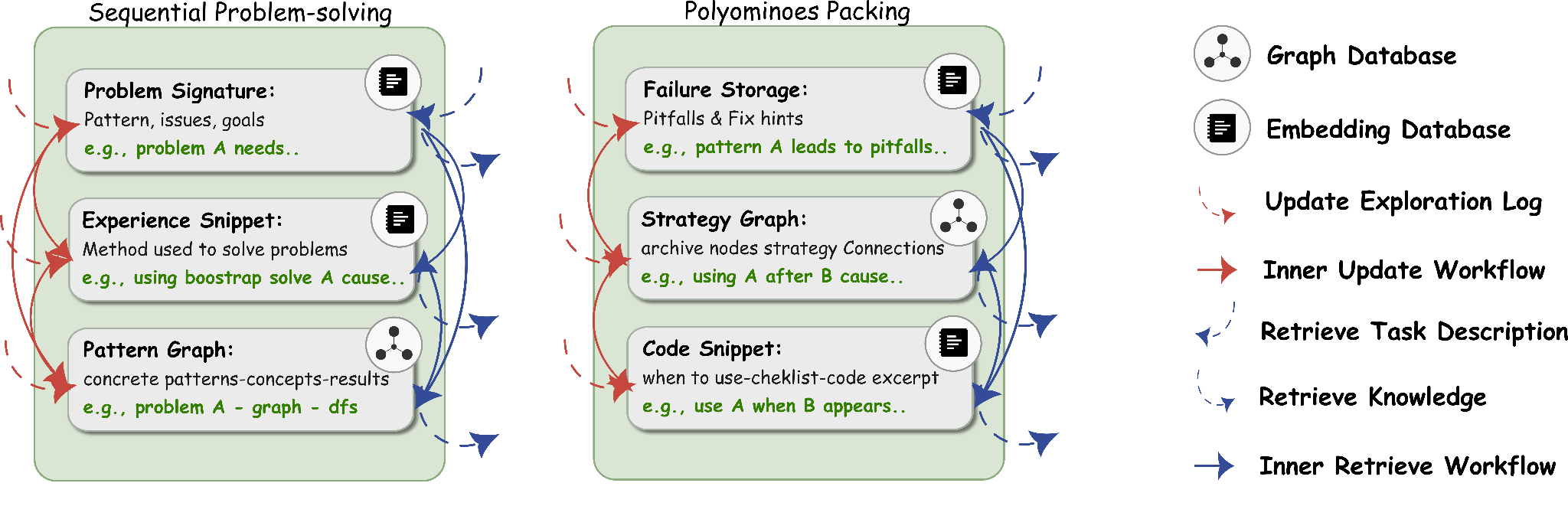
Memory designs for sequential solving emphasize identifying connections across problems, sharing concepts, patterns, and their causal relationships to enhance knowledge transfer. In contrast, memory designs for a single task concentrate on fine-grained, task-specific detail. Different optimization objectives lead ALMA to discover substantially different memory architectures.
Takeaways
A solver in AI-driven automated research should function as a continually learning, agentic system, capable of reusing its accumulated research experience to explore new problems. Our study shows three key trends:
- Memory matters. Adding a learned memory design improves packing density by +6.3pp on a single task and score@1 by +7pp in sequential transfer, showing the gains from continual learning.
- Objective shapes not just memory, but memory designs. The way memory is updated, retrieved, and stored may differ based on research objectives, even when using the same past experiment logs. Task-specific depth and cross-problem generalization require distinct memory architectures.
- Automated discovery works. ALMA’s Meta Agent can discover effective memory designs end-to-end without hand-engineering, opening the door to continual learning in arbitrary research domains.
We hope this blog encourages further investigation into continual learning for AI researchers and highlights the importance of designing memory and learning systems under diverse research settings. We also invite readers to explore ALMA and experiment with it here.