Evaluating the Hardest CS Problems in the Age of LLMs
Frontier-CS scores solutions on a continuous scale across heterogeneous hardware. This post explains the evaluation architecture behind the leaderboard: hash-based resume, resource-grouped clusters, pinned environments, and the challenges ahead for agentic submissions.
What is FrontierCS?
Frontier-CS is an open-source benchmark of 240 open-ended CS problems with continuous scoring.
Evaluating the Hardest CS Problems in the Age of LLMs

Our 1.0 release introduced 240 open-ended problems spanning algorithmic competition and systems research. The best model scores 46.55 on research tasks; human experts hit 86.99 on algorithmic ones. These numbers appear on the leaderboard, but how are they produced? And why should you trust them?
This post is about what happens after a model writes its solution and before a score shows up on the leaderboard. For open-ended CS problems, evaluation is harder than generation.
What is so Hard about Evaluation Anyway?
Traditional coding benchmarks have a simple evaluation story: run the code, check the output, pass or fail. This is true whether you’re talking about LiveCodeBench checking competitive programming solutions, SWE-bench Verified checking if a GitHub issue got fixed, or Terminal-Bench checking if a DevOps task completed. The evaluation is binary, and it doesn’t depend on what hardware you run it on.
Frontier-CS doesn’t work that way. Our problems are open-ended and continuous-scored. Optimize a CUDA kernel to be as fast as possible. Design a cache eviction policy that minimizes miss rate. Implement a parallel sort that scales across cores. There is no single correct answer, only a spectrum from “doesn’t compile” to “beats the reference implementation.”
Evaluating a single problem means provisioning the right hardware, installing problem-specific dependencies, running the solution against a scoring harness, and collecting results. Now multiply that by 7 models, 240 problems, and 5 runs each. That’s 8,400 evaluations per cycle, and a new cycle starts every time a model provider ships an update.

240 Problems, No Two Alike
The 240 problems span two tracks with fundamentally different evaluation needs:
- Algorithmic track (172 problems): C++ solutions judged by a go-judge server against test cases with custom scoring functions. Runs on CPU.
- Research track (68 problems, with 127 evaluators total, since some problems have multiple evaluation criteria): Python solutions that might need GPUs, specific CUDA versions, or custom Python packages installed via
uv. A single problem can take 15 minutes to evaluate.
A CUDA kernel optimization problem needs an A100. An algorithm problem needs nothing more than a CPU and a C++ compiler. You can’t run these on the same machine with the same setup. Provisioning one beefy GPU cluster for everything wastes money. Cramming everything onto one machine wastes time, or simply fails.
We needed an evaluation system that handles this heterogeneity automatically, runs continuously, and produces scores you can trust across months of leaderboard updates. Here’s what we built.
The Architecture in Brief
The system has two layers. SingleEvaluator handles one-off runs: a contributor iterating locally, wanting a quick score. BatchEvaluator handles scale: the weekly CI job that evaluates every model on every problem. Both share the same runners underneath, so a score produced locally via Docker is comparable to one produced in the cloud via SkyPilot.
Runner
├── ResearchRunner (shared validation + config)
│ ├── ResearchDockerRunner
│ └── ResearchSkyPilotRunner
├── AlgorithmicLocalRunner
└── AlgorithmicSkyPilotRunner
The interesting part isn’t the class hierarchy. It’s the set of problems we had to solve to make this work reliably at scale, and why those problems are specific to evaluating LLMs on open-ended tasks.
Four Challenges of the LLM Era
1. Continuous evaluation, not one-shot
Academic benchmarks are typically evaluated once for a paper. Frontier-CS is a living leaderboard. Just in the past few months: Gemini 3.0 Pro, GPT 5.2 Thinking, Grok 4, DeepSeek 3.2. And the pace is accelerating, not slowing down. As we write this, OpenAI has just released GPT-5.3-codex and Anthropic has shipped Claude Opus 4.6. Each new model needs to be evaluated across all 240 problems. That’s thousands of evaluation runs per cycle, and the cycles keep getting shorter.
This forced us to build hash-based resume. Every result records the SHA hash of both the solution file and the problem directory. When a batch is resumed, changed inputs are automatically re-evaluated while unchanged results are kept. Without this, we’d either waste compute re-running everything, or risk publishing stale scores after a problem’s scoring harness gets updated.
2. Heterogeneous hardware at scale
A single batch run might include problems that need an A100 GPU, problems that need a specific AWS instance for HPC workloads (our n-body simulation problems require a c7i.4xlarge with 16 vCPUs for OpenMP parallelism), and problems that need nothing special.
We solve this with resource-grouped cluster pools. Before evaluation starts, pairs are grouped by their ResourceSignature, a tuple of (cloud, accelerators, instance type) derived from each problem’s config.yaml. Each group gets its own pool of SkyPilot clusters, sized proportionally to the number of problems in that group.

CPU-only problems run on cheap instances. GPU problems get GPU instances. No cluster sits idle running the wrong workload.
3. Evaluation determinism
This is the one that keeps benchmark maintainers up at night.
SWE-bench Verified checks whether a patch makes tests pass. LiveCodeBench checks whether a solution produces the right output. Those scores are the same whether you run them on a laptop or a cloud VM. Our problems are latency-sensitive. The score is how fast your code runs, how much throughput it achieves, how efficiently it uses the hardware. Swap an A100 for an H100, and every number on the leaderboard changes.
This makes our evaluation environments far more complex than even the most sophisticated agentic benchmarks. SWE-bench Verified’s environment is a git repo and a test suite. A Frontier-CS research problem might require a specific GPU, a pinned CUDA version, custom Python packages, and a large dataset pre-loaded into memory. Setting up a single problem’s environment can be more involved than SWE-bench’s entire evaluation pipeline.
The RL community learned how fragile this can be when MuJoCo and Gym version upgrades silently invalidated years of published baselines.
Our answer is to pin everything and invalidate aggressively. Each problem’s config.yaml locks down the hardware spec, CUDA version, and runtime environment. The execution environment itself is pinned via Docker images and AMIs, so every run sees the exact same OS, drivers, and libraries. We also encourage problem contributors to design evaluators with deterministic scoring: given the same solution and the same environment, the score should be reproducible. Every evaluation result is then tagged with hashes of both the solution and the entire problem directory (including the evaluator code and config). If anything changes, the hash changes, and all affected scores are automatically invalidated and re-run.
We don’t try to make scores portable across environments. Instead, we guarantee that every valid score on the leaderboard was produced under the same pinned conditions. Determinism through immutability, not through cross-environment normalization.
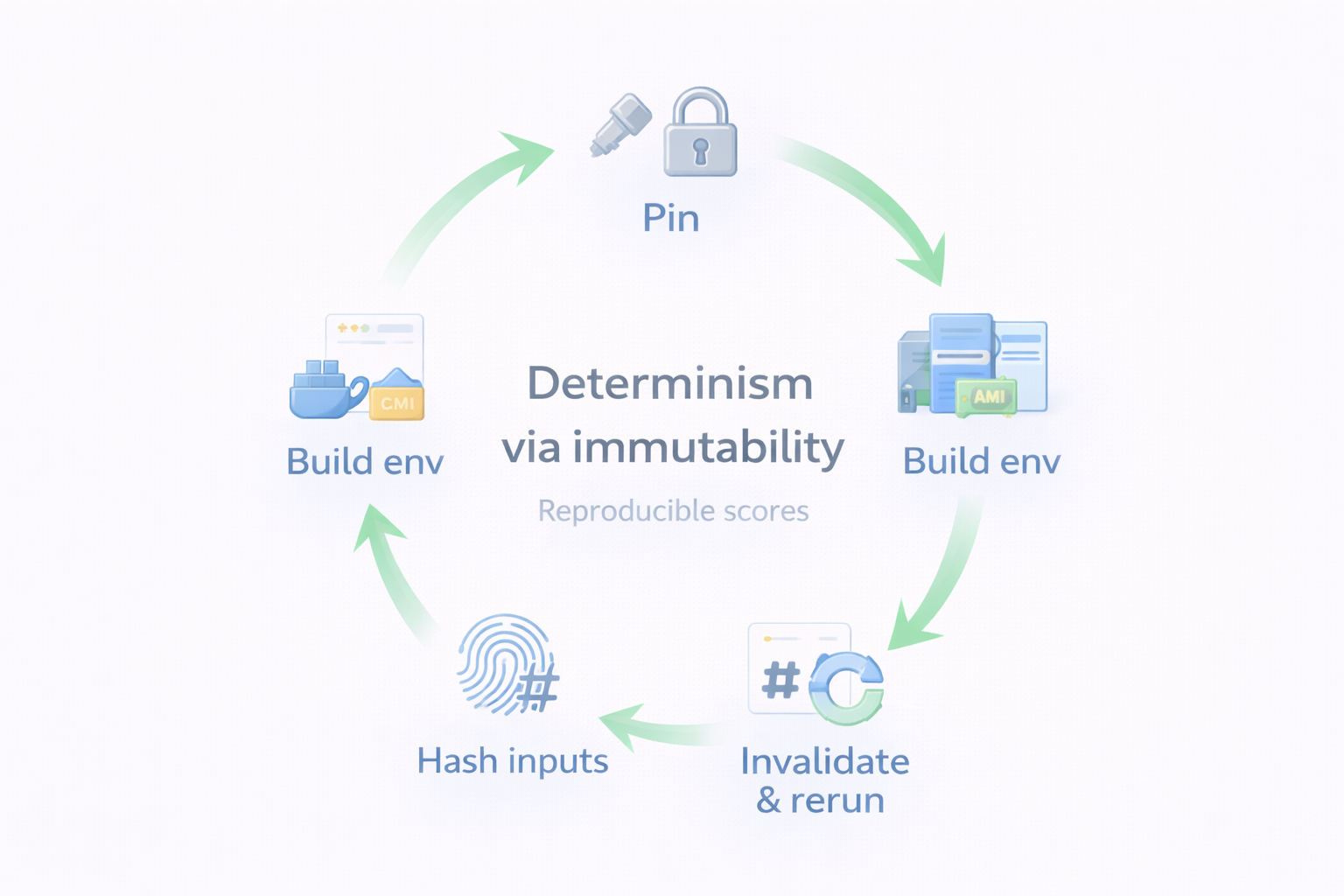
Evaluation determinism is becoming a first-class concern across the benchmarking community. Projects like CocoaBench are pushing this idea further, building frameworks specifically around reproducible evaluation environments. We think this is the right direction.
4. Generation ≠ Evaluation
Many LLM benchmarks tightly couple generation and evaluation: call the API, get the output, score it immediately. We deliberately decouple them.
The gen/ module calls LLMs and writes plain source files (solution.py or solution.cpp). The evaluation pipeline doesn’t know or care which model wrote the code, what prompt was used, or how many attempts it took. Each evaluation runs in an isolated container or VM: solutions cannot see each other, cannot read test cases, and cannot access the network.
Why does this matter? A human expert can drop a hand-written solution into the same directory and it gets evaluated identically. You can compare different prompting strategies, different temperatures, or different models on exactly the same evaluation path. And because each run is sandboxed, there’s no way for a solution to game the evaluator by reading other solutions or probing the scoring harness. The scoring is model-agnostic and tamper-resistant by design.
Looking Ahead: Agentic Submissions
The clean separation above also forces us to confront a question the community is only starting to grapple with: what happens when the submission is an agent, not a file?
Today, a submission to Frontier-CS is a source file. But the frontier is moving toward agentic workflows where the model reads the problem, writes code, runs it, inspects the output, and iterates. The generation process itself has side effects: it reads the environment, runs tests, modifies code across multiple turns. The boundary between “generating a solution” and “evaluating it” starts to blur.
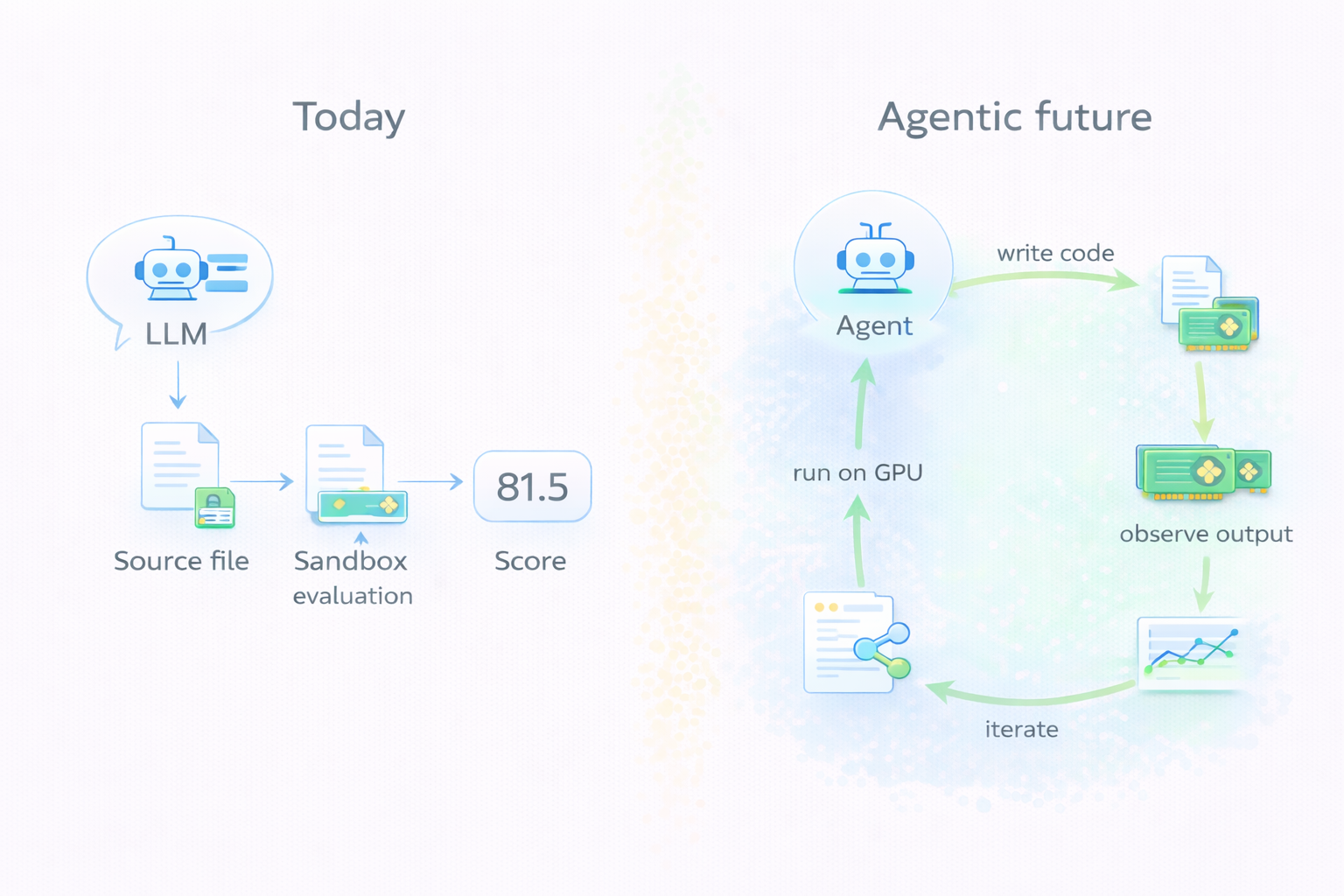
Our current architecture handles this by keeping the boundary sharp: no matter how the solution was produced (single-shot, chain-of-thought, 50 rounds of agentic iteration), what enters the evaluation pipeline is still a source file. The agent’s process is its own business; we only score the artifact.
But as agents get more capable, two challenges loom.
First, reward hacking. An agent that iterates against a scoring harness is doing what any good engineer does: profile, optimize, repeat. The risk is that as agents get stronger, they overfit harder. And not all overfitting is equal. An agent that discovers temporal locality in a cache trace and designs a policy around it has learned something real. An agent that memorizes the specific access pattern in the test set and hardcodes a lookup table has learned nothing. Both produce high scores. Only one generalizes. The stronger the agent, the greater the risk of spurious overfitting, and the more pressure on us to design evaluation data that faithfully represents the real problem, so that gaming the harness and genuinely solving it become indistinguishable.
Second, the cost model breaks. Right now, generation (API calls) and evaluation (GPU compute) are cleanly separated. You call the API, get a file, and schedule GPU time whenever it’s convenient. With agentic submissions, the agent needs to write code, run it on a GPU, inspect the results, and iterate. The GPU cluster has to stay alive while the agent thinks and makes API calls. You’re burning two expensive resources simultaneously, and each one is idle while waiting for the other. This is fundamentally a co-scheduling problem between API latency and GPU utilization, and it doesn’t have an obvious solution yet.
What a Batch Run Looks Like
Here’s what happens when the weekly CI job runs:
frontier batch research --workers 10 --clusters 10 --backend skypilot
- Discover pairs: scan the solutions directory, match each solution file to its problem.
- Check hashes: compare solution/problem hashes against stored results. Skip unchanged pairs; invalidate stale results.
- Group by resources: partition pairs by
ResourceSignature. A CUDA kernel problem and a CPU algorithm problem land in different groups. - Create cluster pools: provision SkyPilot clusters for each group, proportionally allocated.
- Dispatch: workers pull pairs from a shared queue, acquire a cluster from the matching pool, run the evaluation, return the cluster.
- Record: each result is saved with its hashes. Interrupted runs resume from exactly where they left off.
The same pipeline runs for the algorithmic track, with a go-judge server instead of SkyPilot clusters.
What This Enables
- The leaderboard stays honest. Every score is tagged with environment hashes. Stale results are caught automatically. Failures are tracked via status metadata, not silently recorded as score = 0.
- Contributors can validate locally.
frontier evalruns the same scoring logic on your laptop (via Docker) that the CI runs in the cloud. - New models get evaluated fast. Hash-based resume means only new or changed pairs are evaluated. Right-sized cluster pools mean no wasted compute.
Try It Yourself
git clone https://github.com/FrontierCS/Frontier-CS.git
cd Frontier-CS && uv sync
# Evaluate a single problem locally
frontier eval research flash_attn solution.py --backend docker
# List all available problems
frontier list
For the full architecture details, see ARCHITECTURE.md in the repo.
Getting in Touch
We are always looking for more problems to add for our next release and evaluating on more models and agents. We love to hear about your comments and feedback! Join us on discord or email us!
And if you find Frontier-CS useful, please consider giving us a star on GitHub!