Frontier-CS 1.0 Release
We are releasing Frontier-CS 1.0, a major update to our open-ended Computer Science benchmark. This release expands Frontier-CS to 240 tasks across both the algorithmic and research tracks. We also introduce a new Elo-based leaderboard, along with full execution traces of model solutions to enable deeper analysis and reproducibility.
![]()
We’re excited to announce the release of Frontier-CS 1.0! Frontier-CS is an open-ended benchmark designed for evolving intelligence. It now comprises 240 unsolved problems (+94 since Dec 2025), spanning a diverse range of computer-science domains and are authored by CS PhDs and ICPC World Final–level experts.
Frontier-CS supports benchmarking frontier models, agent-based evaluation, algorithm evolution, post-training, and beyond - any setting where progress is measured by quantitative, fine-grained metrics that reflect solution quality, rather than binary pass/fail outcomes.
Why Frontier-CS?
By 2025, LLMs have largely saturated exam-style benchmarks in computer science. We now see near-perfect performance on standardized evaluations: ~80% on SWE-bench Verified, gold-medal–level results at the 2025 ICPC World Finals, and strong scores across many exam-style tasks. While useful, these benchmarks no longer capture meaningful progress in the development of foundational models and various modes of problem solving.
In light of that, Frontier-CS is motivated by two gaps. First, we need open-ended tasks that never saturate, so that progress can be continuously made and reflects long-horizon planning, code writing, and genuine skills in problem-solving—not binary pass/fail accuracy hacking. Second, with the rise of evolution and agentic frameworks (e.g., AlphaEvolve, ADRS, TTT-style discovery), we need a large-scale, verifiable benchmark that enables comprehensive comparison and provides training signals toward scalable agents for scientific discovery, including agentic RL.
So how do the models do?
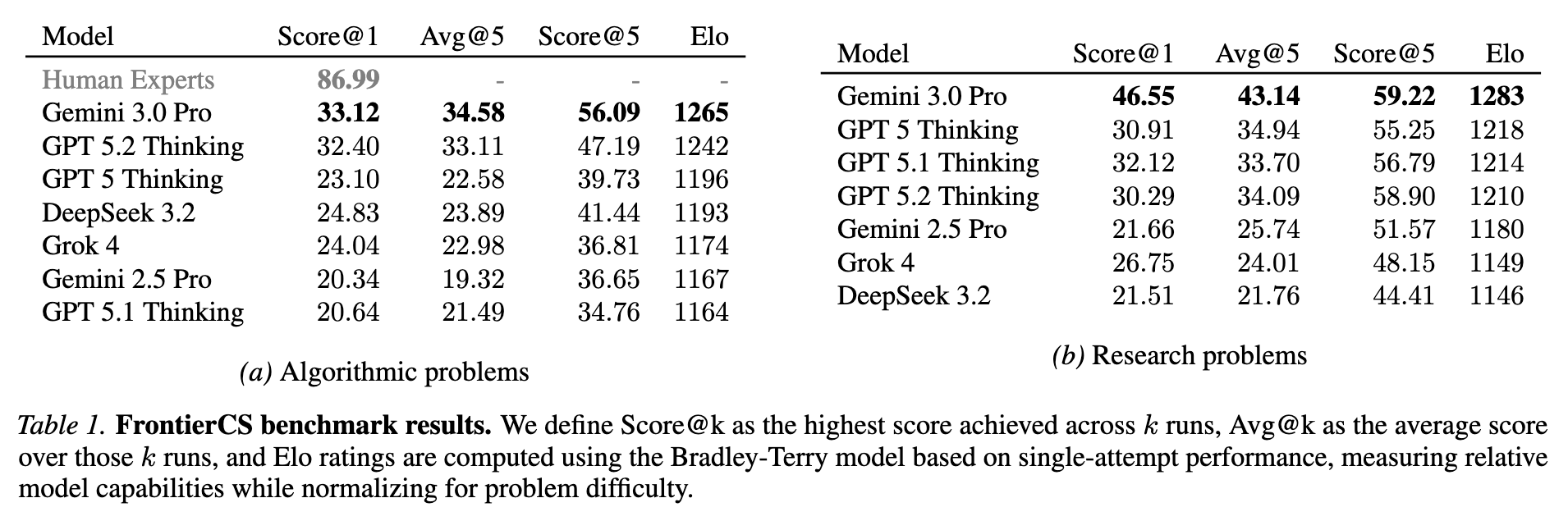
Crafted by several ICPC World Finalists and CS PhDs, Frontier-CS has 240 problems which are open-ended, verifiable, and diverse (varying 7 research domains and 3 algorithmic engineering categories). Surprisingly, even though modern models have nearly aced traditional computer science benchmarks, they still struggle with the open-ended nature of Frontier-CS. On the algorithmic track, human expert solutions achieve an average score of 86.99, while the strongest model reaches only 33.12. This substantial gap remains far from closed. We’ll go into the details of our results in a later post, but for now check out our leaderboard.
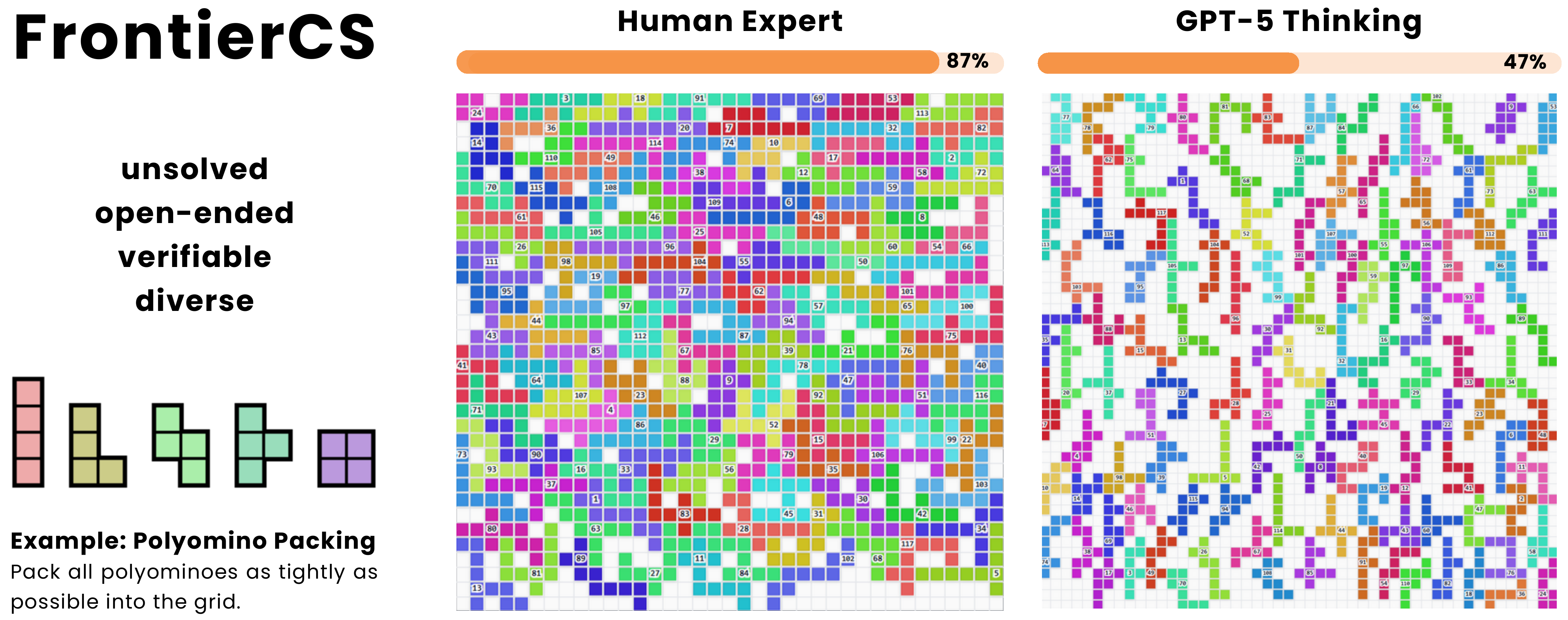
What’s New in Frontier-CS 1.0
-
Expanded Problem Set: Frontier-CS now includes 240 problems, an increase of 94 since December 2025. This expansion spans a broader range of computer science topics and challenges. For example, we introduce two new software-engineering fuzzing tasks, where models must design fuzzers that maximize code coverage under a fixed budget. We also added more algorithmic problems, including several classical NP-hard challenges and tasks adapted from the latest competitive programming contests.
-
Enhanced Evaluation Metrics: In this update, we introduce Elo ratings to Frontier-CS. This addition is motivated by a simple issue with raw scores in open-ended benchmarks: they are often hard to interpret across problems with vastly different difficulty and scoring ranges. For example, it is unclear how to compare a model that outperforms another by 10 points on one problem with one that wins by only 1 point on a different problem. Elo ratings address this by focusing on relative, pairwise performance rather than absolute score magnitudes, resulting in a leaderboard that better reflects overall model capability and remains stable as new problems are added.
-
Releasing model trajectories: We release over 3,000 solution trajectories from seven frontier models evaluated on Frontier-CS, including GPT-5.2, GPT-5.1, GPT-5, Gemini 3.0 Pro, Gemini 2.5 Pro, Grok-4, and DeepSeek-3.2. These trajectories enable fine-grained analysis of model behavior and provide a valuable resource for future research on model understanding and performance improvement.
-
Enhanced user experience: We’ve refined the Frontier-CS workflow to make evaluation simpler and more intuitive. Solutions can now be evaluated with a single command or through a clean, easy-to-use API, with complex, problem-specific environments unified into a consistent execution interface without setup by users.
git clone https://github.com/FrontierCS/Frontier-CS.git
cd Frontier-CS
# Install dependencies (using uv, recommended)
uv sync
# Run the example solution (GPT-5 Thinking Solution)
frontier eval --algorithmic 0 algorithmic/problems/0/examples/gpt5.cpp
- Agentic Frameworks: We are exploring the integration of agentic frameworks into Frontier-CS (e.g., OpenEvolve), and we welcome submissions of agent results to our leaderboard.
Getting in Touch
We are always looking for more problems to add for our next release and evaluating on more models and agents. We love to hear about your comments and feedback! Join us on discord or email us!
And if you find Frontier-CS useful, please consider giving us a ⭐ on GitHub!