Your Next Long-Context Recipe: Open-Ended Problems
We integrate FrontierCS into Harbor and release a preview long-horizon agent leaderboard on 178 open-ended algorithmic tasks. Kimi K2.6 and Claude Code Opus 4.7 show similar headline capability, but very different failure modes.
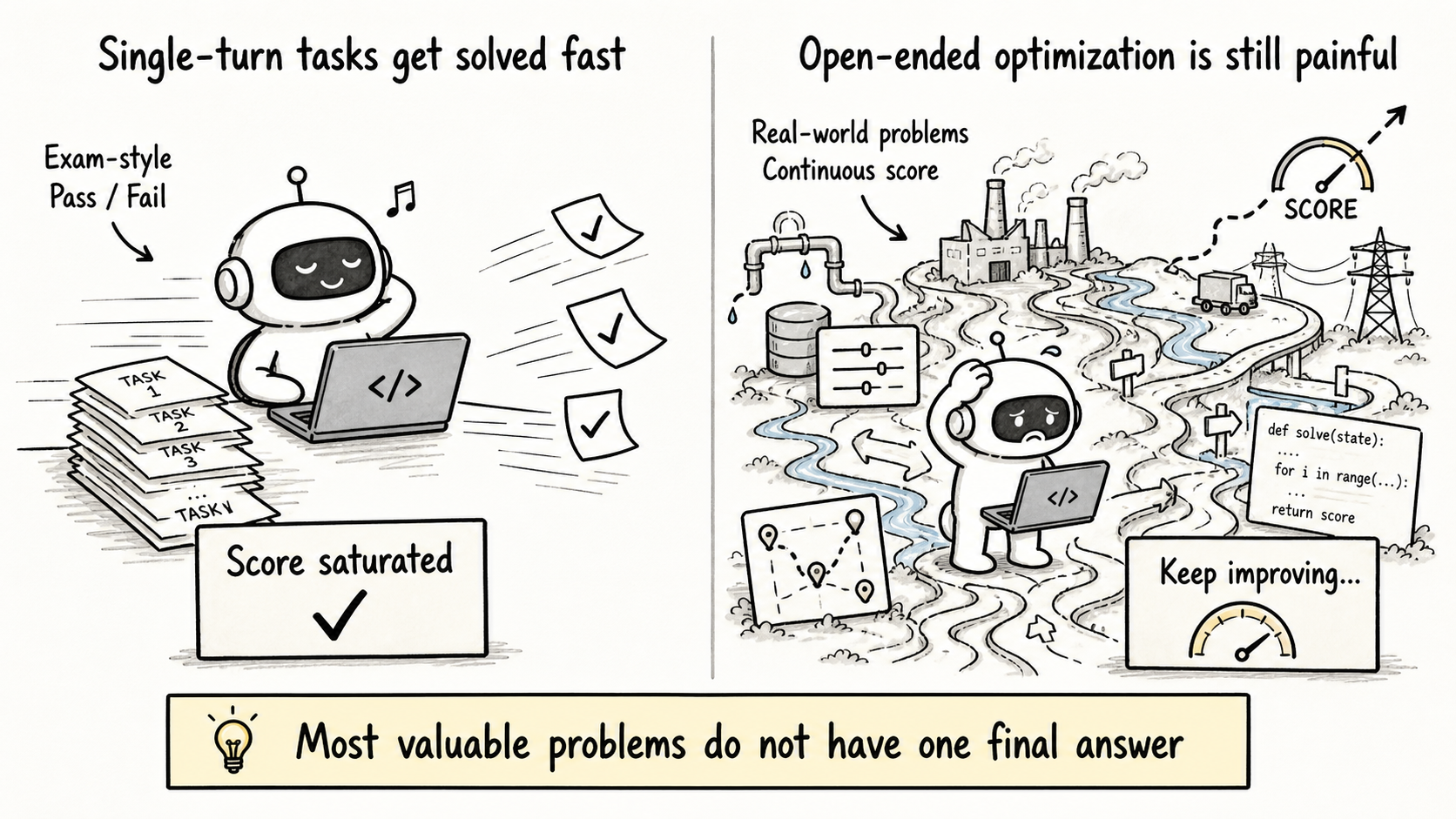
As we get closer to the second half of 2026, one thing feels increasingly clear to us: frontier labs are paying less attention to single-call exam-style questions: math questions, programming contest problems, and simple software bug fixes. Frontier models are saturating these tasks quickly, and the marginal value of these tasks is also going down.
The next opportunity may be in open-ended system optimization.
Think about low-level AI kernel optimization, database tuning, large-scale logistics planning, or power grid scheduling and decision-making. These problems rarely have a single correct answer. But improving the current best solution, by even a small amount, can create real social value and commercial impact.
This was the core motivation behind FrontierCS. We wanted the LLM community to move some of its attention away from increasingly boring exam-style leaderboards, and toward open-ended problems that are closer to economically viable agentic optimization problems that people care about.
Why Open-Ended Optimization
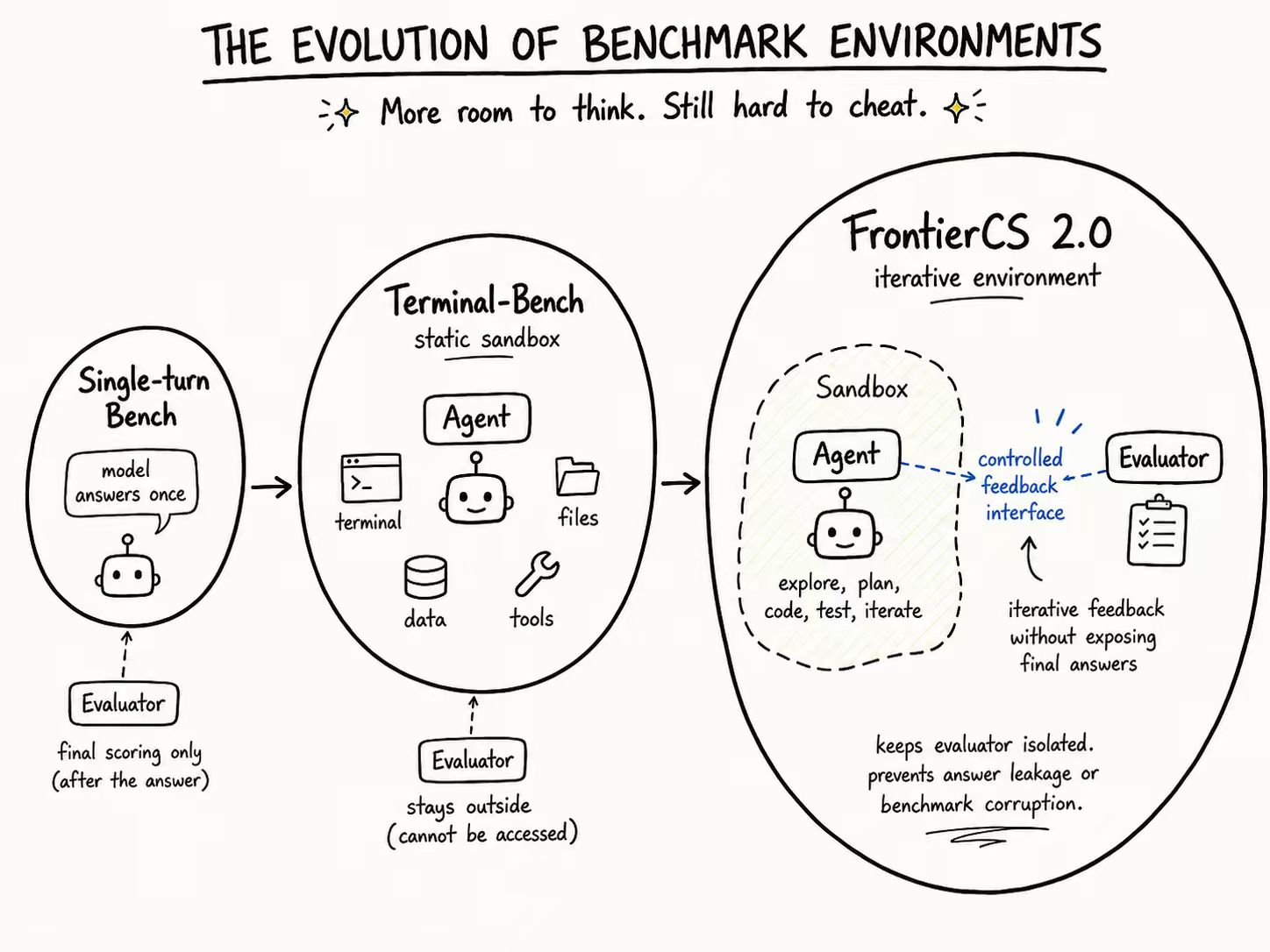
The difficulty is that real-world open problems are deeply coupled with complex environments. They are hard to scale for training or evaluation. When we want to build hundreds or thousands of such tasks systematically, fully recreating the real environment is often not feasible.
So we made a tradeoff: extract the core algorithmic challenge behind each real-world open optimization problem, and put it into a clean, controllable, evaluable environment. The tasks look as standardized as programming contest problems. They can be automatically evaluated, and each solution receives a continuous numerical score. Fundamentally, they are about continuously improving the best solution found so far in an open search space.
In this work, we collaborated with dozens of CS PhDs from top schools and ICPC World Finalists, spent four months designing 240+ such tasks, and systematically measured the performance of frontier models.
We found that these open-ended optimization tasks are extremely long-horizon for today’s code agents. In our measurements with Kimi K2.6 and Claude Code Opus 4.7, it was common for a single task to run for 500+ steps. Even then, the final agent performance was still not satisfying and remained far from human expert solutions.
Human experts can do very well on these tasks. A recent example is Tact Smart Battle 1, a Codeforces smart-contract optimization contest with a $20,000 prize pool. In such problems, strong human problem solvers still outperform agents when the task is open-ended and engineering-heavy.
This may be one of the most important problems for the second half of LLMs in 2026: as long-horizon agents become a major trend, AI agents still cannot reliably optimize the kinds of problems humans actually care about. What they are best at today is imitating known human solutions, answering questions, and fixing code. They are much weaker at continuously discovering better solutions in an open space.
Example: Polyomino Packing
One concrete FrontierCS task is polyomino packing: given a set of pieces, maximize the area of the pieces packed into the grid. This is a well-known combinatorial optimization problem that is NP-complete.
The animation below shows the kind of progress we want to measure. Starting from a simple baseline, an adaptive evolution agent gradually discovers better ordering, symmetry handling, and local compaction:
A solver gradually discovers denser polyomino packing strategies.
From FrontierCS to Harbor
That is why we integrated FrontierCS into Harbor, and are releasing a preview version of a long-horizon agent leaderboard.
Harbor is an existing agent evaluation framework. By integrating FrontierCS-style open-ended optimization tasks into Harbor, we can launch, run, and score them through a unified workflow. The agent enters the task environment, reads the problem, writes code, runs experiments, observes scores, and iterates. This is much closer to the workflow we care about: repeatedly generating solutions, using feedback, and continuing to optimize.
This is also why we are releasing a preview leaderboard. Beyond the final score, we care about how today’s long-horizon code agents behave on open-ended optimization problems: whether they can keep improving, where they get stuck, and when they start going in circles.
Preview Leaderboard
In this preview leaderboard, we evaluated Kimi K2.6 and Claude Code Opus 4.7 on 178 FrontierCS algorithm tasks. Each task has a continuous score, and the agent’s goal is to improve that score as much as possible under a given step, time, or token budget. The final ranking matters, but the process matters more: how many ideas the agent tries, whether it recovers from failed experiments, whether it converges too early to a mediocre solution, and when its improvement curve flattens.
Metric
Claude Code Opus 4.7
Kimi K2.6
Tasks
178
178
Partial Score
43.0
46.9
Avg. Steps
77.2 (max 482)
67.2 (max 835)
Avg. Turns
53.6 (max 339)
67.2 (max 835)
Avg. Output Tokens
251K (max 660K)
156K
Avg. Thinking Calls
—
67.1 (max 835)
Avg. Tool Calls
42.2 (max 281)
70.6 (max 875)
Zero-Score Tasks
69 / 178
58 / 178
Token Limit Hit
31
0
In these latest traces, Kimi K2.6 gets a partial score of 46.9, while Claude Code Opus 4.7 gets 43.0. Both agents solve 21 tasks perfectly, but Kimi has fewer zero-score tasks: 120/178 tasks receive a positive score, compared with 109/178 for Claude.
Kimi is slightly ahead in final score on this set of runs. The traces show a sharper difference. Claude takes more steps on average, uses 251K output tokens per task on average, and hits the token/output cap in 31 zero-score runs. Kimi uses fewer output tokens on average, 156K, while making more tool calls: 70.6 per task, compared with 42.2 for Claude.
Failure Modes
Agent
Failure reason
Count
Share among zero-score tasks
Claude Code Opus 4.7
token/output cap
31
44.9%
Claude Code Opus 4.7
compile error
10
14.5%
Claude Code Opus 4.7
timeout
8
11.6%
Claude Code Opus 4.7
not directly attributable from trace
20
29.0%
Kimi K2.6
compile error
22
37.9%
Kimi K2.6
timeout
22
37.9%
Kimi K2.6
runtime / crash
3
5.2%
Kimi K2.6
not directly attributable from trace
11
19.0%
We made an initial classification of zero-score tasks using verifier details, trial logs, and error messages visible in the trajectories. The most obvious takeaway is that the two agents fail differently. It is important to note that the token/output cap and timeout here are not tight constraints: the token/output limit is set very high, and each run has a full 5-hour timeout. Claude’s 31 token/output-cap failures therefore look more like a long-horizon control problem. In some tasks, it appears to get stuck inside a thinking step, spending a huge amount of budget on long outputs or long internal reasoning without producing a valid final submission. Kimi’s zero-score failures are more concentrated around engineering reliability: 22 compile errors and 22 timeouts. It more often pushes the attempt toward executable code, but does not reliably pass the verifier.
These failure modes give us a more concrete read on the current state of frontier code agents. They can produce good solutions on some open-ended tasks, but stable long-horizon optimization is still missing. Claude’s issues are closer to budget control and long-trajectory convergence; Kimi’s are closer to engineering reliability and final submission quality.
What Comes Next
Next, we will keep expanding FrontierCS coverage on Harbor, add more agents and models, and release more trajectory-level analysis. The question we care about is simple: when an AI agent is placed in an environment with no single correct answer, where progress may require hundreds of optimization steps, how far is it from a truly strong human researcher?
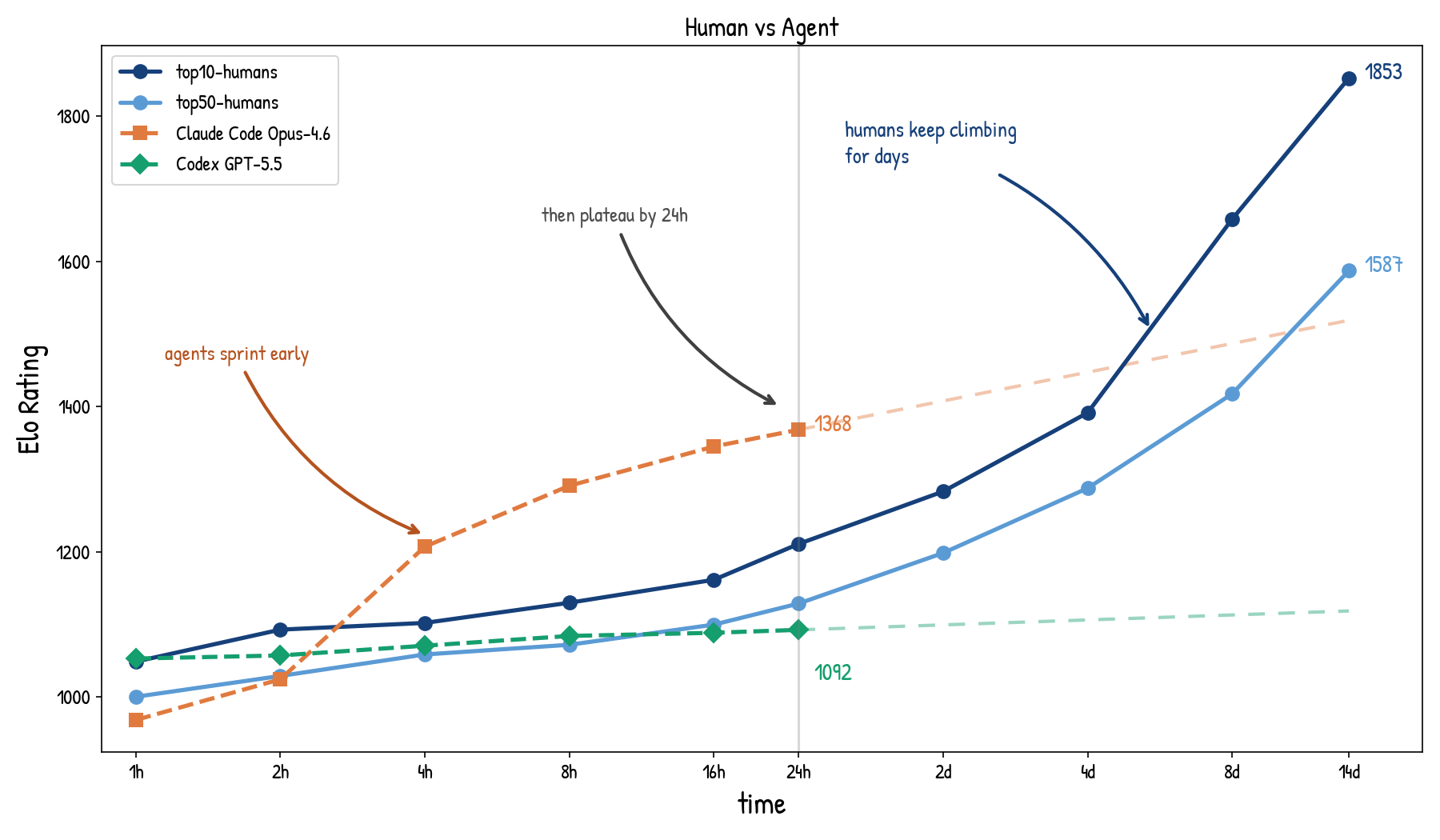
Agents can spend test-time compute by trying, observing, and revising. We derive an Elo reference for repeated sampling, then show that in a 2022 two-week coding marathon, current agents plateau within 24 hours while top humans keep improving.
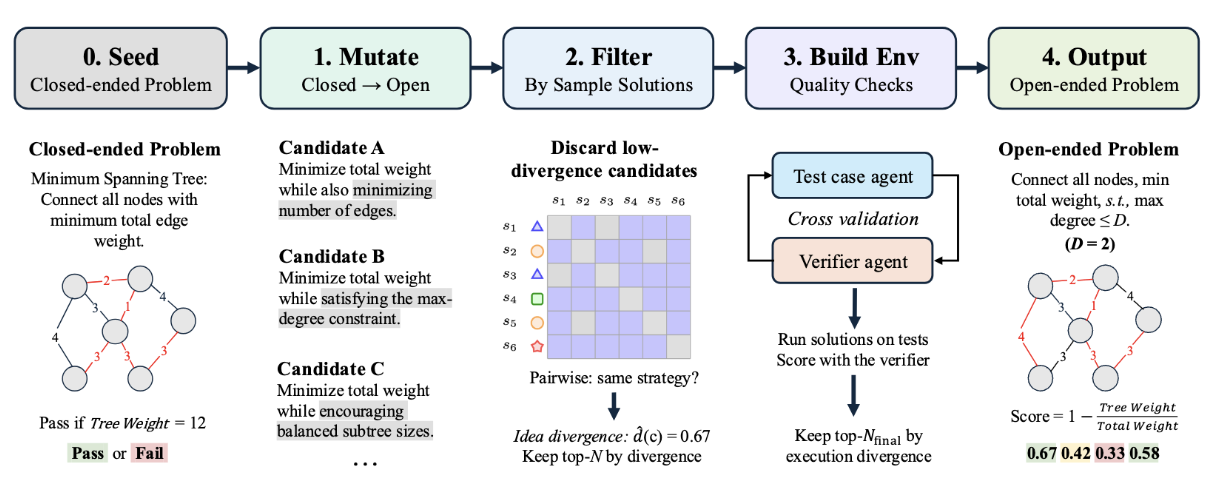
We release FrontierSmith, a system that converts closed-ended coding problems into open-ended optimization tasks for training long-horizon coding agents.