LLM Defeated in Open-ended Problems
Modern LLMs claim superhuman algorithmic abilities, but what happens when there is no strict verifier? We analyze how multi-turn 'optimization' in Frontier-CS exposes the cognitive ceiling and catastrophic failures of AI in open-ended problem solving.
According to official technical reports, Deep Think’s model achieves a Codeforces elo rating of 3455. Our independent evaluation estimates Deep Think’s actual rating to be roughly 3299. However, during the open-ended AtCoder Heuristic Contest (AHC), the model only managed non-zero scores on under 50% of the problems — a strong contrast to its performance on traditional algorithms. We conducted detailed cause analysis and case study based on the result.
The Real-World Evaluation Gap
In actual working environment, a consistent trend has been noticed widely: Modern LLMs’ (etc. Deep Think) effectiveness in actual work environments isn’t nearly as outstanding as their amazing performance on traditional algorithmic benchmarks shows.
Unlike solving standard competitive programming problems with fixed boundaries, real-world work fundamentally tests a model’s capacity for continual learning and adaptation. There is a significant mismatch between current model behaviors and what traditional algorithmic benchmarks actually measure. To truly evaluate a model’s ability to handle complex, ambiguous scenarios, we must test it using open-ended problems.
To illustrate this, we evaluated Deep Think on two entirely different tracks: 30 of the newest Codeforces problems with a high difficulty rating of 2500+ (representing traditional, strict-boundary algorithmic tasks), alongside all 33 short-format problems from the AtCoder Heuristic Contest (representing open-ended, heuristic challenges).
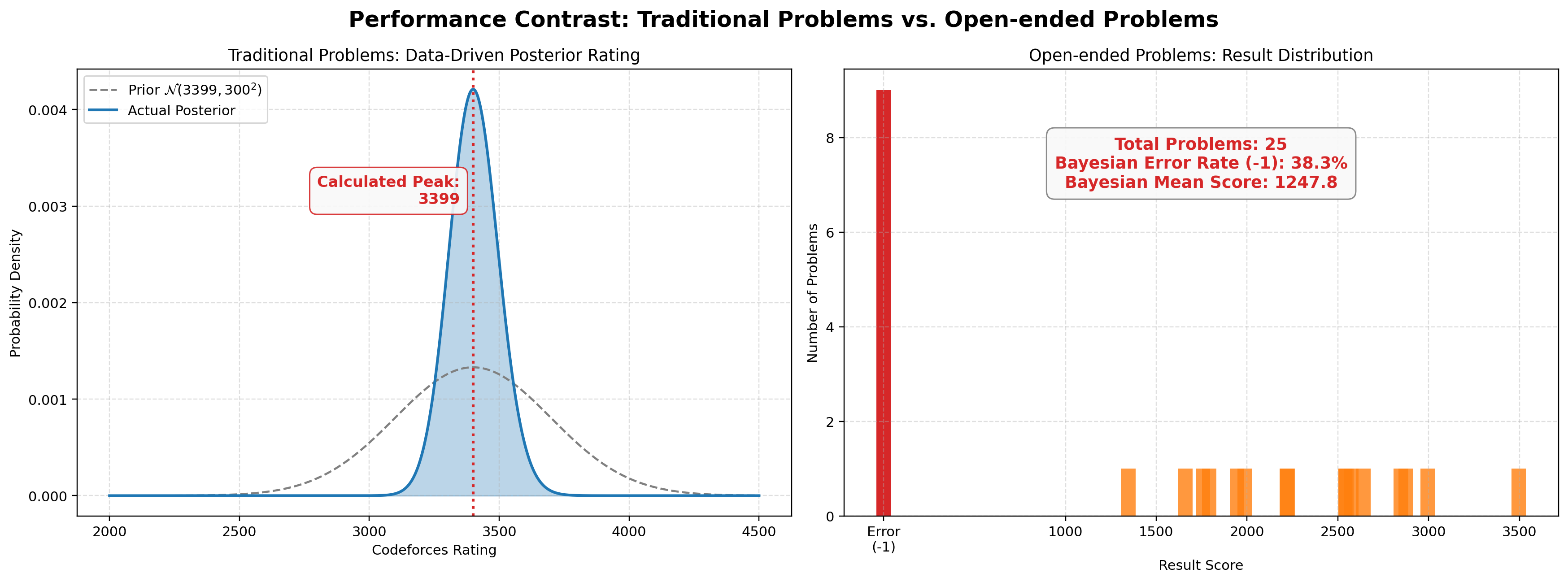
The data reveals a suprising contrast. We found that the model produces a massive volume of failure cases when attempting open-ended heuristic problems, given it’s near human. This high failure rate completely mismatches the model’s supposedly superhuman, high-confidence performance in traditional algorithmic domains.
To understand exactly why this breakdown occurs and how models fall into these optimization traps, we conducted a detailed case study.
Case Study: The Hedgehog Graph
To understand this collapse, let’s look at a specific interaction involving the interactive problem Hedgehog Graph (no. 222).
- The Setup: You are given a directed graph with 1,000,000 vertices. Each vertex has exactly one outgoing edge, eventually flowing into a single directed cycle.
- The Goal: Determine the length of the cycle, S.
- The Tool: You can make queries
? v x, returning the vertex reached by taking x steps from v. - The Constraint: You have a budget of 2500 queries.
- The Score: Using 500 or fewer queries yields 100 points. The score decays quadratically up to 2500 queries, after which the score drops to 0.
Round 1: The Robust Solution
In its first attempt, the model defaulted to a highly stable, probabilistic approach based on the Birthday Paradox. It queried random step sizes, stored the resulting vertices, and looked for collisions.
\[E[\text{queries}] \approx \sqrt{\frac{\pi}{2} S}\]For a cycle of 1,000,000 vertices, the expected number of queries is roughly 1200. This is a mathematically robust baseline. It doesn’t matter if S is prime or composite; the logic holds. The model correctly noted this would yield a partial score of around 20 points, well within the 2500 absolute limit.
Round 2: Incorrect Optimization
A human competitor at this stage would secure the 20 points and attempt to safely optimize the constant factors or memory usage. The LLM, prompted to improve its score, took a wildly different path. It abandoned the stable baseline entirely for a “Scaled Collision” strategy.
The model attempted to split its query budget into stages, testing highly composite numbers to exploit number theory and artificially force faster collisions.
- Stage 1: Try factors of primes up to 47 for 220 queries.
- Stage 2: Try factors of primes up to 43 for 220 queries.
- Fallback: Use the remaining budget for random collisions.
The Anatomy of the Trap
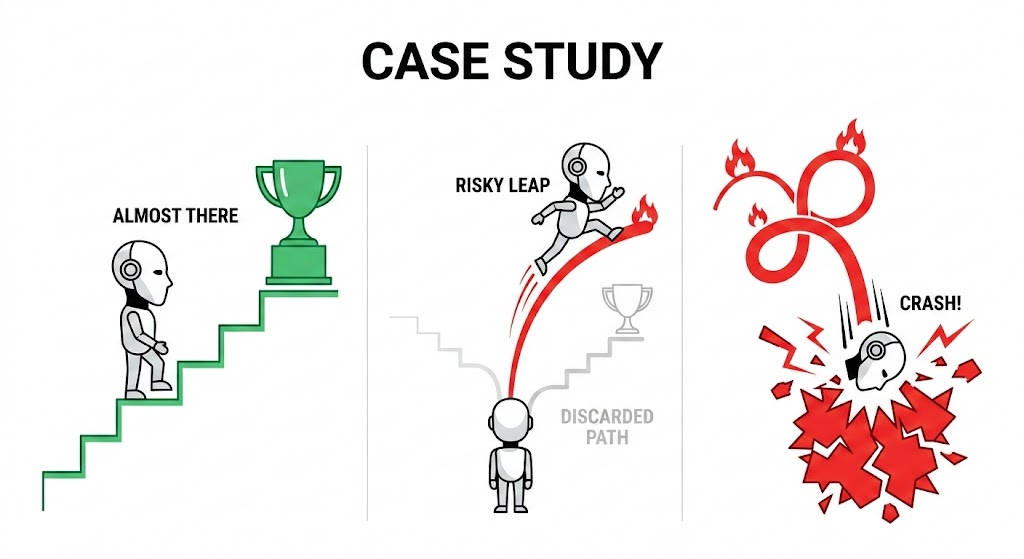
This looks like sophisticated engineering, but it is a catastrophic theoretical failure.
The LLM optimized purely for the average case (composite numbers) while entirely blinding itself to the worst case (prime numbers). If the cycle length S is a large prime like 999,983, it shares no factors with the model’s composite guesses. The effective cycle length remains unchanged, and the “optimization” yields zero benefit.
Then as a result, the model fragmented its strict query budget. By the time it realized its heuristic trick was failing on prime numbers, it had wasted 800 queries. Starting the fallback random search with a massive 800-query debt pushed the total past the 2500 limit.
The result: A stable 20-point baseline was “optimized” into a 0-point failure.
The Post-Training Flaw
This behavior highlights a profound issue with modern LLMs. During post-training, AI institutions frequently optimize for state-of-the-art benchmark scores by artificially encouraging the model to take risks instead of stable choices. By generating multiple diverse rollouts and selecting only the highest-scoring one—a technique known as Best-of-N sampling—the training process disproportionately rewards high-variance, speculative logic over safe, incremental improvements. Consequently, the fully trained model naturally defaults to risky, “all-or-nothing” gambles rather than stable optimization methods.

When faced with a difficult optimization task lacking a strict, immediate verifier, the model resorts to a “lazy” strategy. Instead of doing the grueling work of designing a universally stable improvement, it speculates. It chooses unstable, point-cheating tricks that create the illusion of problem-solving but performs terribly under the pressure of strong, worst-case test data. The model effectively hit a cognitive ceiling, opting for giving an incorrect optimization rather than acknowledging the limits of its reasoning.
Real-World Implications
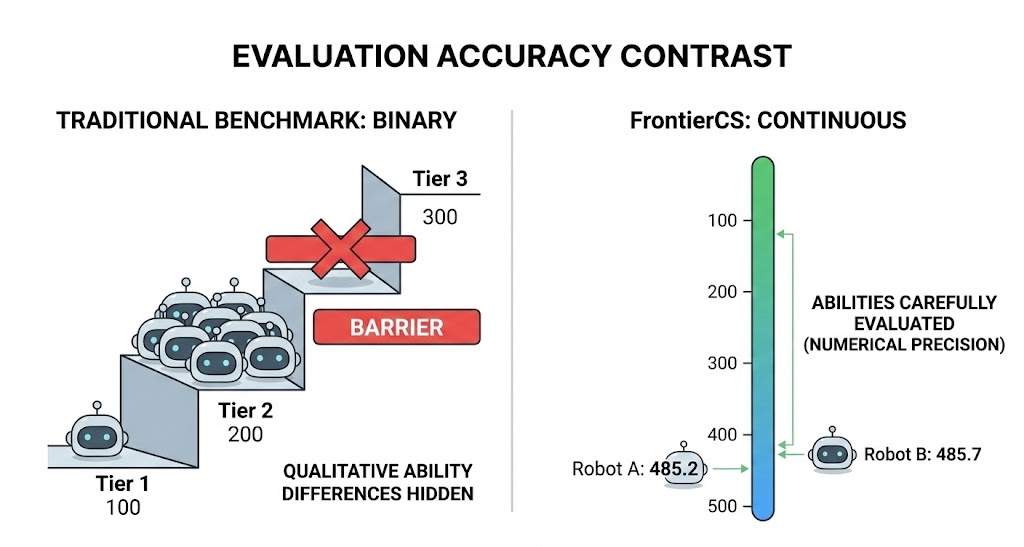
This is why continuous scoring in benchmarks like Frontier-CS is critical. In a binary pass/fail system, this regression might be masked.
More importantly, the open-ended problems in Frontier-CS reveals the realities of actual software engineering. Production codebases and complex system architectures do not have a absolute, formal verifier. If we trust LLMs to autonomously optimize systems without strict bounds, they are highly intended to introducing fragile, edge-case-blind logic that works in theory but causes systemic collapse in practice.
While LLMs undoubtedly possess elite capabilities for isolated, well-defined algorithms, their performance in open-ended reasoning remains fundamentally unreliable. Treating them as omnipotent architects rather than powerful, specialized tools is a trap we cannot afford to fall into.