Frontier-CS Goes Live: 2,000 Humans vs. AI on an Open-Ended Problem
We placed an open-ended optimization problem in CALICO, UC Berkeley's official programming contest. To score, you had to beat a frontier AI. Out of 2,000+ contestants, only one submission surpassed the strongest AI agent.
×
We placed an open-ended optimization problem in CALICO, UC Berkeley's official competitive programming contest with 2,000+ human participants. The challenge: beat the AI. Out of all contestants, only one submission surpassed the strongest AI agent.
What is CALICO?
CALICO (CALICO Informatics Competition) is the official competitive programming contest hosted by a group of UC Berkeley students interested in competitive coding at the end of each semester. The group consists of a variety of members who each contribute in different aspects, including serious competitive coders who compete in ICPC, students who have taken CS 170 who want to learn more about competition, an infrastructure team that maintains the website and servers during the contest, and a hardworking logistics team that plans meetings, finds sponsors, and manages the in-person contest. The contest is co-organized with ICPC@Berkeley and Upsilon Pi Epsilon (UPE), a UC Berkeley EECS student organization affiliated with the EECS department. The contest runs on a custom judge platform built on top of DOMjudge, the same open-source system used at the ICPC World Finals.
The most recent contest took place on April 11, 2026, drawing 1,714 contestants across 836 teams from 44 countries and 23 states. The contest featured 12 problems split into 20 test sets, with 7,528 total submissions received. This edition marks CALICO’s fifth ever in-person contest — a tremendous milestone. CALICO is especially proud of the continued growth of the in-person division, which attracted notable participants including tourist (Gennady Korotkevich, the world’s #1 ranked competitive programmer) and many high school students making the trip to Berkeley’s campus.
The in-person event was a full-day experience. Participants arrived to a check-in table where they picked up contest merch, then kicked things off with an interactive puzzle hunt — a multi-page web adventure where teams solved riddles and puzzles across linked pages to unlock the next clue. The opening ceremony featured director opening remarks, a guest speaker talk by Michael Cruz, a senior software engineer at Disney, and a sponsor talk by X-Camp. Competitors then dispersed into rooms and worked in teams of 2–3 to tackle the 3-hour contest.
Winners of the interactive puzzle hunt before the contest.
The event closed with a resolver ceremony: submissions from the last 30 minutes of the contest were hidden on the live scoreboard and revealed one by one in reverse order, each update potentially reshuffling the standings in dramatic fashion. The ceremony was followed by a raffle and placement prizes for top finishers.
The in-person division was won by Bar of Camp (Yiming Li and Xianghong Luo, software engineers at Google). The online division was won by Do You Like Hacks (Nelson Huang, Jason Sun, and Yujia Gong). All contestant submissions from this contest are available at github.com/calico-team/calico-sp26-submissions.
Bar of Camp (Yiming Li and Xianghong Luo), winners of the in-person division.
In-person contestants competing during CALICO at UC Berkeley.
The CALICO team with tourist (Gennady Korotkevich), the world's #1 ranked competitive programmer.
The Problem
Frontier-CS is an open-ended, continuously-scored benchmark for AI on hard CS problems. This spring, Frontier-CS contributed one problem to CALICO. To score, you must beat an AI.
Given $M$ noisy observations of off-diagonal entries in an unknown $N \times N$ multiplication table, choose positive integers $a_1, a_2, \ldots, a_N$ and a discard set $S$ with at most $D$ elements to solve:
where each observation $k$ specifies a row index $r_k$, a column index $c_k$, a target value $v_k$, and an importance weight $w_k$.
The problem is NP-hard in general. In the largest test cases, $N = 4 \times 10^3$ and $M = 2 \times 10^6$, with a time limit of 10 seconds.
Left: the reconstructed multiplication table for $\mathbf{a} = [2, 3, 4, 4]$. Right: the equivalent graph formulation. The problem reduces to assigning node values that minimize weighted relative error across all edges.
Beat the AI
Rather than judging submissions against a fixed optimal answer, the problem uses a “beat the AI” scoring model. Three AI baselines define three difficulty levels. To clear a level, your penalty must be lower than the AI’s on every test case.
How hard is that? The AI baselines are not toy solutions. They get progressively more sophisticated:
The three AI baselines, in order of increasing strength.
Level 1: Grok 4, 121 lines. A greedy spanning-tree heuristic. Grok 4 picks one node as an anchor and propagates values outward, one edge at a time. Fast, but fragile: one bad anchor poisons the entire solution. It even has a floating-point bug that silently disables its confidence metric.
Level 2: GPT-5.4-thinking-high, 377 lines. A weighted-median coordinate descent solver with multi-start initialization. Unlike Grok 4, it uses all observations simultaneously and restarts from three different seeds. After convergence, the worst outliers are discarded and the solver re-runs.
Level 3: GPT-5.4-thinking-high + agentic harness, 533 lines. A six-stage pipeline produced by an open-ended solver agent co-designed by Bo Peng and Qiuyang Mang. The agent iteratively generates, executes, evaluates, and refines solutions over multiple rounds. The final pipeline chains log-domain linearization, robust relaxation, multi-start seeding, real-domain median sweep, integer hill-climbing, and iterative outlier rejection. Each stage hands a better-structured problem to the next.
Takeaway: Stronger models produce longer code (121 → 377 → 533 lines) and deeper pipelines. But the leap to Level 3 is not about a smarter model. It is about long-horizon agentic coding: iterating over many rounds of generation, execution, and refinement to assemble a solution no single-shot model can match.
Results
The contest lasted 3 hours with 12 problems in total, so contestants could only devote a fraction of their time to this problem. We also kept the judge open for one week after the contest to collect additional submissions. The results below include both in-contest and post-contest attempts.
Out of 285 total submissions, only one surpassed the strongest AI agent (Level 3).
The human solutions that cleared Level 2 are strikingly different from the AI baselines. Two examples: one team used a square-root heuristic that simply estimates each $a_i \approx \sqrt{v_k}$ and averages, ignoring the graph structure entirely. Another team ran 7 passes of coordinate descent seeded from medians, essentially a simpler version of GPT-5.4’s approach without multi-start or interleaved outlier rejection.
Takeaway: Human submissions average only 125 lines, with no deep pipelines or stacked tricks. Beating an AI baseline does not require a more complex solution, just a different one. Where AI builds elaborate multi-stage architectures, humans find short, direct paths that exploit structural weaknesses the AI overlooked.
Conclusion
The agentic harness beat nearly every human, but at a cost: hundreds of tokens and a 533-line pipeline. Humans averaged just 125 lines. Can we learn from how humans iteratively refine solutions to open-ended problems, and use those trajectories to teach agents better long-horizon coding strategies?
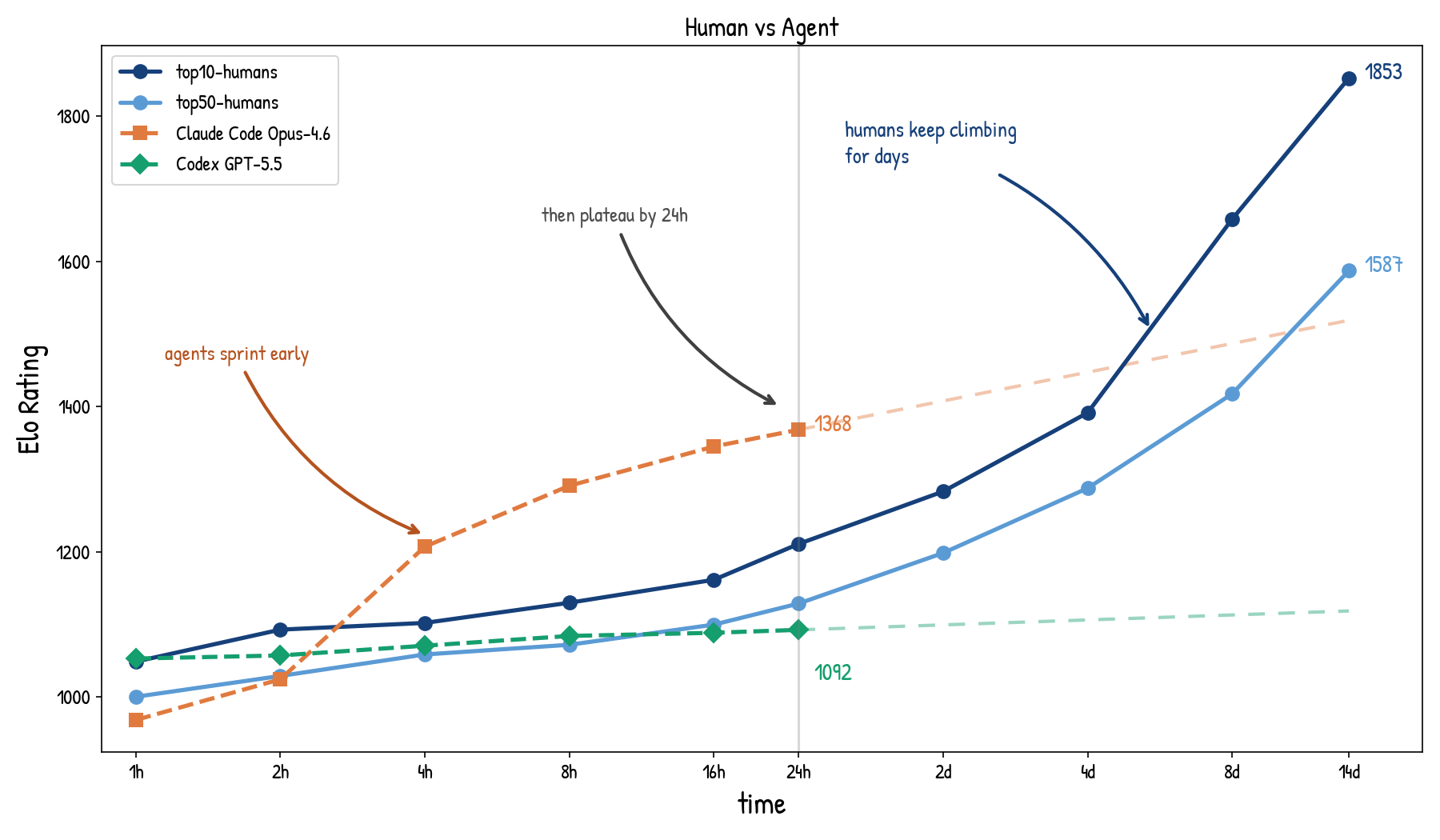
Agents can spend test-time compute by trying, observing, and revising. We derive an Elo reference for repeated sampling, then show that in a 2022 two-week coding marathon, current agents plateau within 24 hours while top humans keep improving.
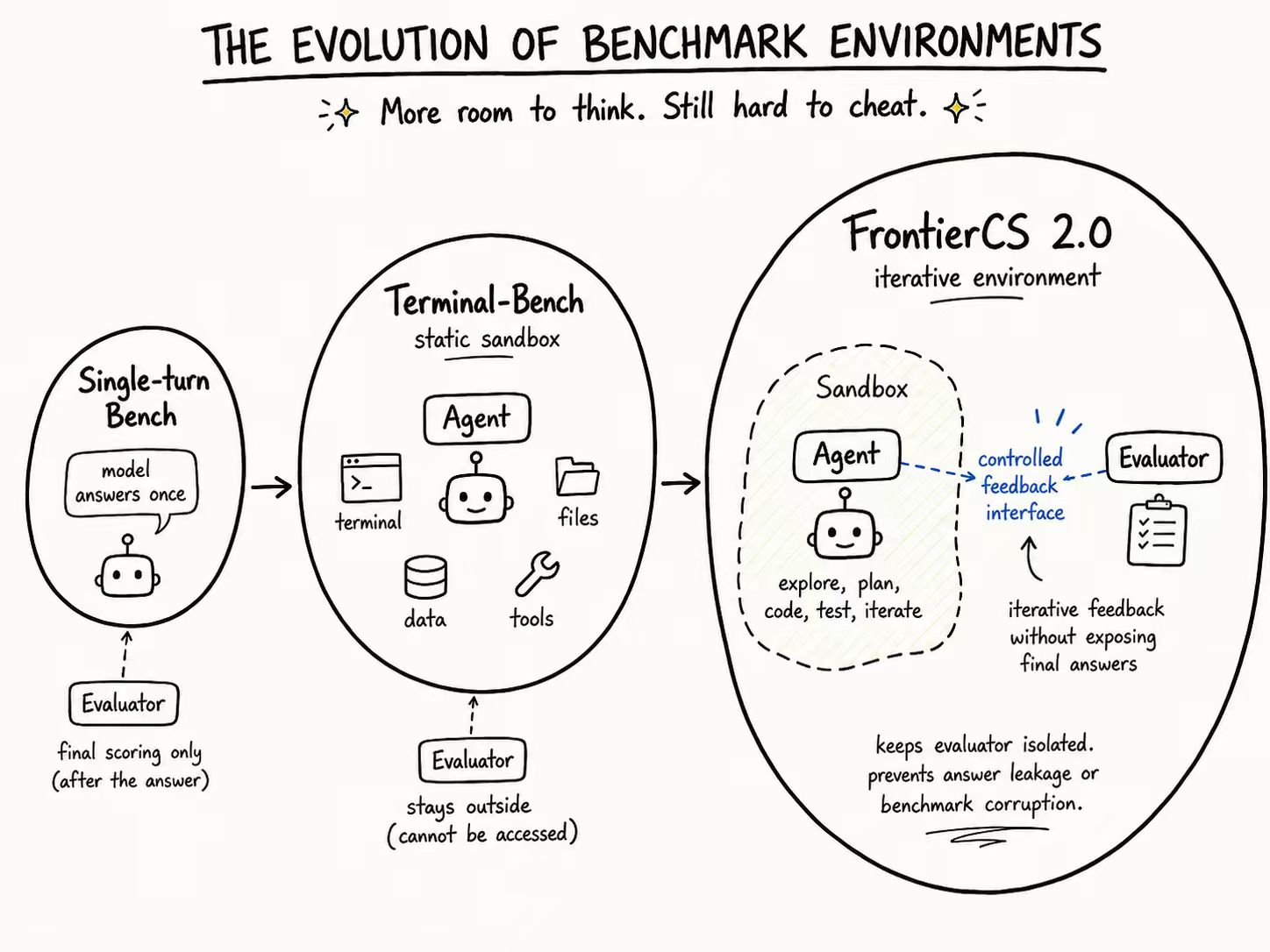
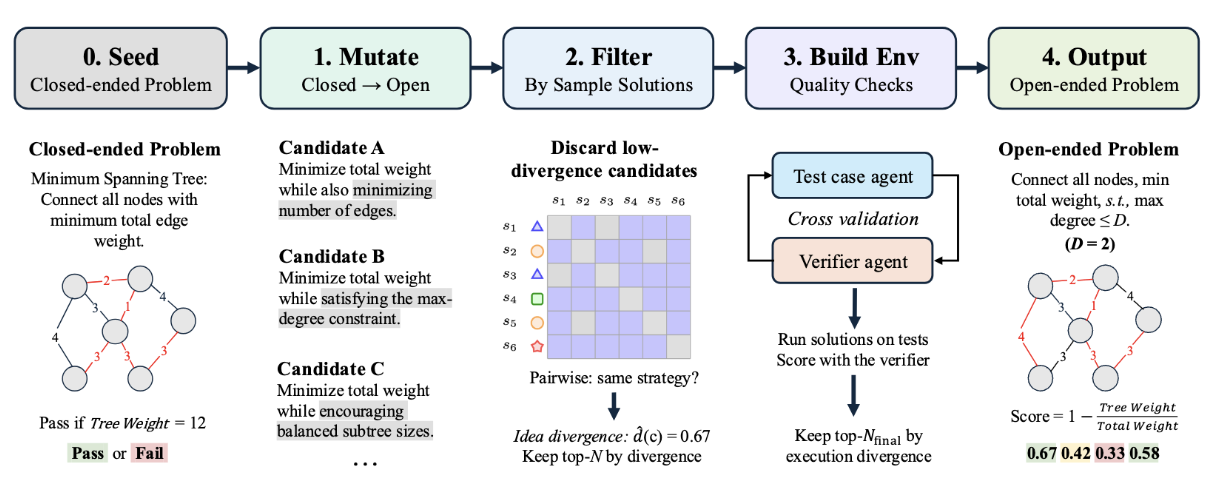
We release FrontierSmith, a system that converts closed-ended coding problems into open-ended optimization tasks for training long-horizon coding agents.