FrontierSmith: Synthesizing Open-Ended Coding Problems at Scale
We release FrontierSmith, a system that converts closed-ended coding problems into open-ended optimization tasks for training long-horizon coding agents.
TL;DR. We are releasing FrontierSmith, a system for synthesizing open-ended coding problems at scale. Starting from closed-ended programming tasks, FrontierSmith produces optimization-style problems with continuous scores, filters them for real solution diversity, and builds runnable training environments. In our experiments, models trained on FrontierSmith data can outperform models trained on human-curated open-ended data, and the resulting tasks elicit genuinely long-horizon agent behavior.
The Data Bottleneck
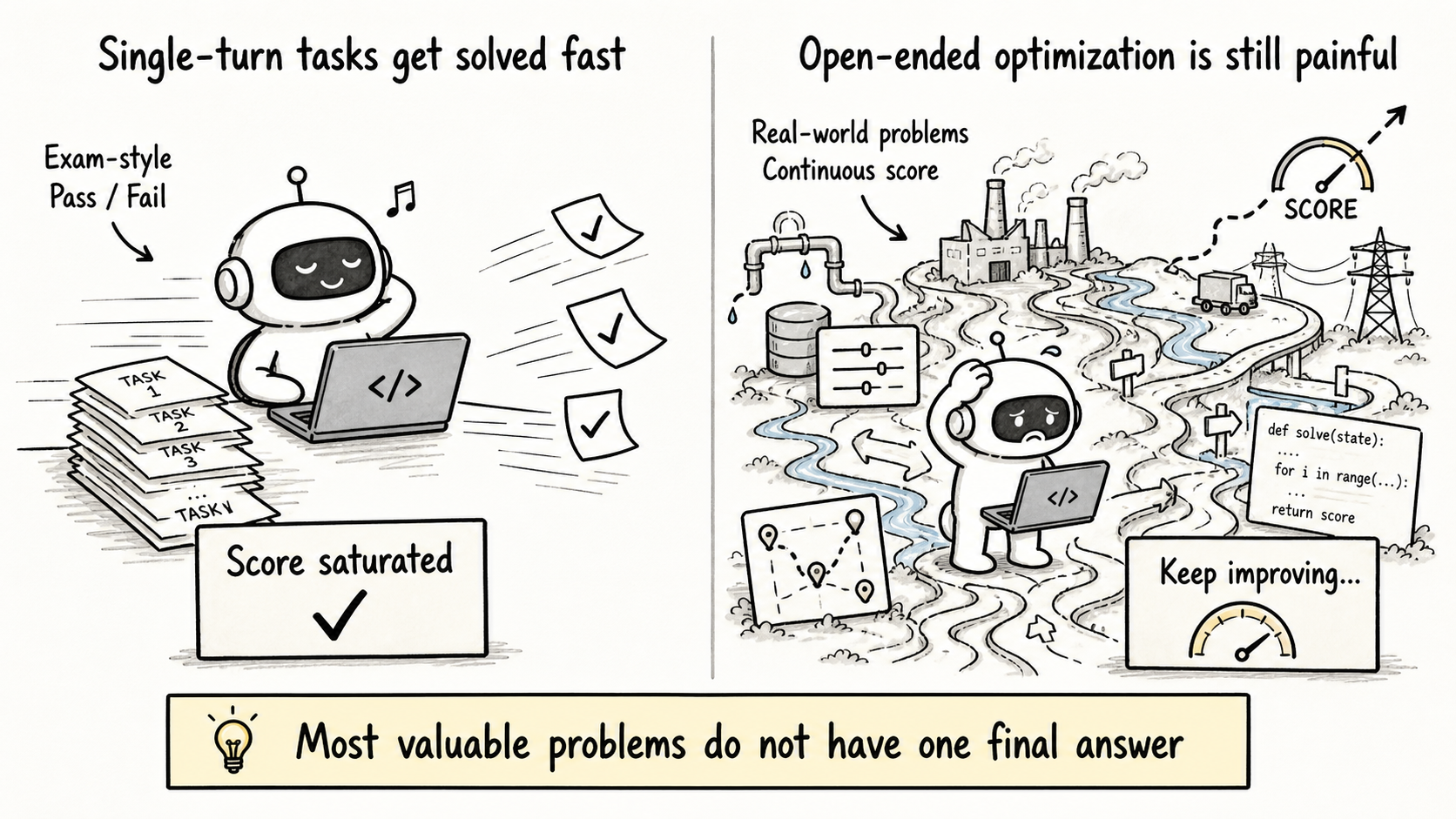
Code agents are getting very good at repetitive software work. Across research labs and startups, the next important question is increasingly about whether AI can solve open-ended optimization problems that matter in the real world: chip placement and routing, logistics, power-grid scheduling, database tuning, kernel optimization, and many others.
But our previous FrontierCS on Harbor blog showed a clear weakness. Today’s code agents are much less reliable in long-horizon, open-ended optimization than they are on traditional contest or math-style tasks.
We think a major reason is data.
Classic RLVR settings have huge amounts of high-quality training data. Competitive programming alone has more than 100,000 public problems, and the broader coding-data industry is continuously producing more. By contrast, if we add together open-ended optimization benchmarks such as FrontierCS, ALE-bench, KernelBench, and the recent MLS-Bench, we still only get hundreds of tasks.
Closed-ended coding data is abundant. High-quality open-ended coding tasks are still rare.
That gap is the bottleneck FrontierSmith targets. Frontier labs may already understand the value of open-ended optimization, but without enough scalable training tasks, it is hard to run the kind of training that made closed-ended coding models so strong.
From Closed to Open
The core idea of FrontierSmith is simple: do not ask an LLM to invent high-quality open-ended problems from scratch. Start from closed-ended problems instead.
Closed-ended coding tasks are already abundant. Given a LeetCode-style or competitive-programming-style problem, FrontierSmith applies principled mutations that turn it into a high-quality open-ended optimization problem.
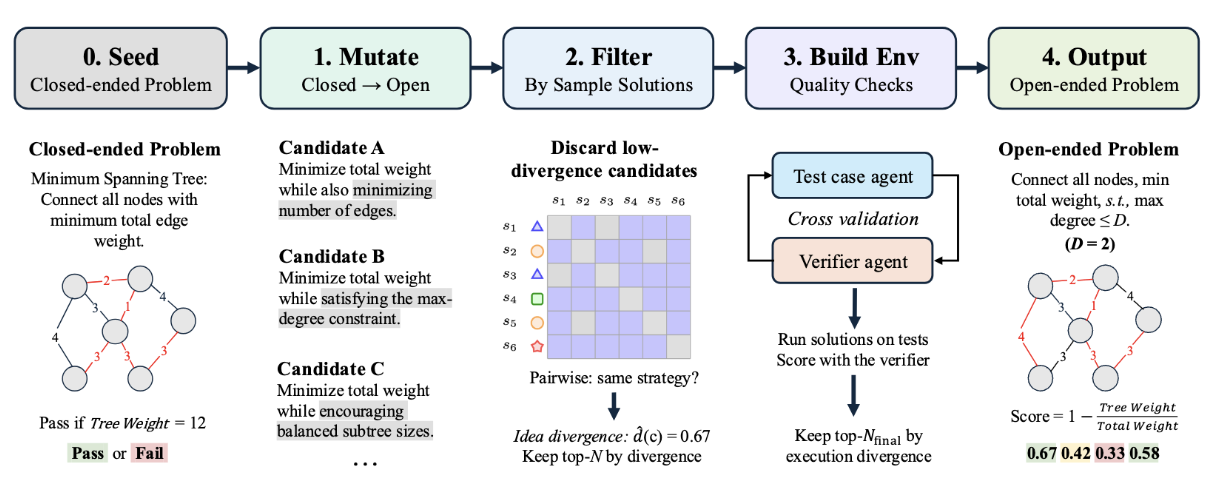
FrontierSmith starts from closed-ended seed problems, mutates them into open-ended candidates, filters them by solution diversity, and builds runnable training environments.
We describe a problem as a tuple: an objective $O$, input constraints $C_I$, and output constraints $C_O$. FrontierSmith mutates the formulation along three axes:
Changing the goal $(O \rightarrow O’)$: replace an exact or binary goal with an optimization objective.
Restricting the output $(C_O \rightarrow C_O’)$: add constraints that make exact solutions infeasible at scale.
Generalizing the input $(C_I \rightarrow C_I’)$: relax input assumptions so a previously tractable problem becomes hard.
FrontierSmith mutates problem formulations by changing goals, restricting outputs, or generalizing inputs.
A simple example is minimum spanning tree. The original problem has a clean greedy solution. If we add a degree constraint and require every vertex in the tree to have degree at most $D$, the problem becomes a degree-constrained spanning tree problem. When $D = 2$, this reduces to a classic TSP-like setting. At realistic scales, exact optimality is no longer practical, and solution quality becomes continuous.
Filtering for Real Diversity
Mutation creates many candidates, but not every candidate is useful. Some are still effectively closed-ended. Some are open-ended in wording but dominated by one obvious strategy.
Our key filtering signal is idea divergence. We cannot ask an LLM to prove whether a problem is P or NP-hard, or whether an optimum is reachable under a fixed compute budget. We can, however, sample solutions from different solvers and ask whether they explore meaningfully different algorithmic ideas.
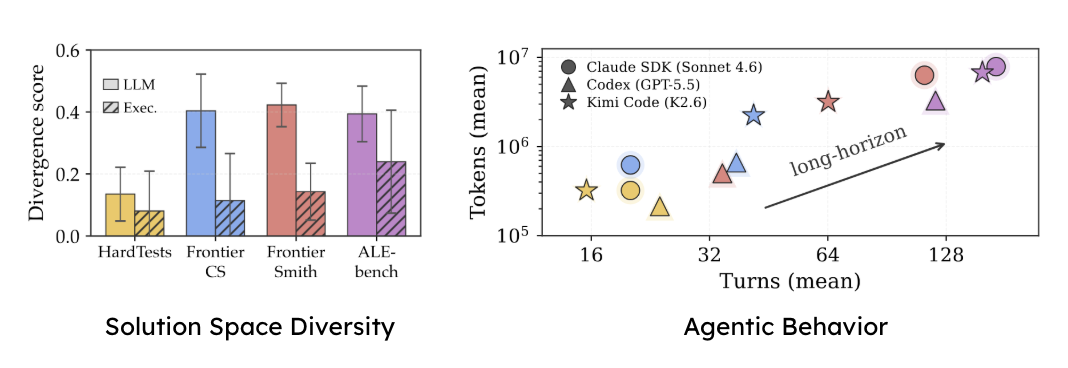
Open-ended problems tend to produce diverse solution strategies. Closed-ended problems are often dominated by a single “gold idea.”
Idea divergence is estimated both semantically, by comparing solver strategies, and behaviorally, by comparing score vectors across generated tests.
FrontierSmith uses this signal in two stages. Before building an execution environment, an LLM judge compares sampled solutions and estimates whether they use the same strategy. After tests and verifiers are built, FrontierSmith also compares solution score vectors across test cases. Candidates with low divergence are discarded.
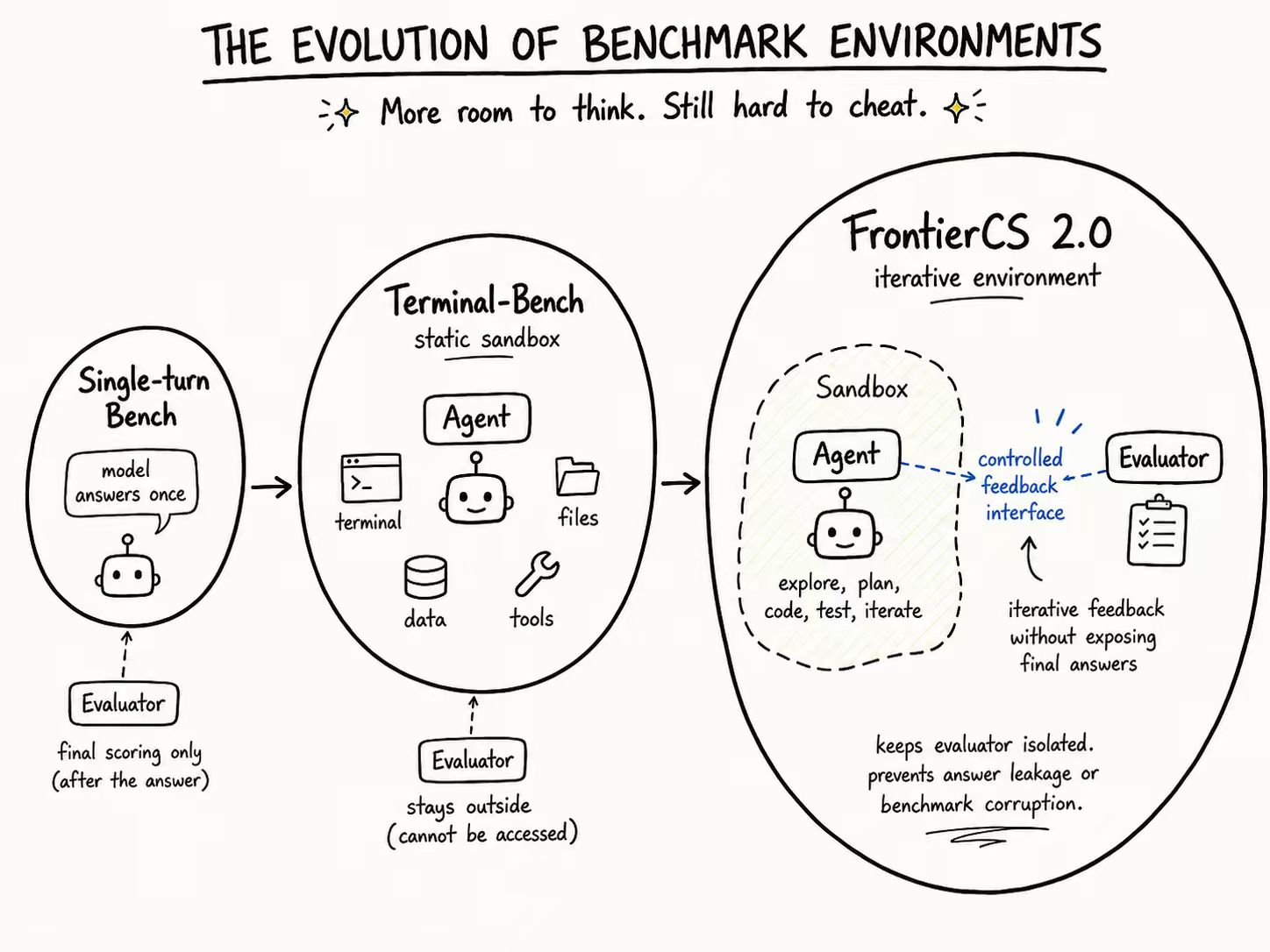
Building Training Environments
The surviving ideas are converted into clean, runnable training environments. We reuse the FrontierCS judge sandbox and generate two pieces for each task:
A test-case generator.
A verifier that returns a normalized score in $[0, 1]$.
For scoring, FrontierSmith uses a simple baseline-normalization scheme. For a task, we generate a trivial baseline solution. Suppose the baseline obtains objective value $x$, and a submitted solution obtains $y$. For a minimization problem, a normalized improvement score can be computed as:
with the analogous form for maximization. Crashes, timeouts, and invalid outputs receive zero. This gives the RL system a continuous reward instead of binary pass/fail feedback.
Experiments
We evaluate on two open-ended coding benchmarks:
FrontierCS, using the 172 algorithmic open-ended tasks.
ALE-bench-lite, derived from AtCoder Heuristic Contest-style optimization tasks.
For training, we synthesize 200 FrontierSmith problems and run GRPO on Qwen3.5-9B and Qwen3.5-27B. We compare against several controls: training on human-curated FrontierCS problems, training on ALE-bench, training directly on 200 closed-ended HardTests problems, and training on FrontierCS with random rewards.
The results are direct. FrontierSmith-generated data is strong enough to match or exceed human-curated open-ended training data.
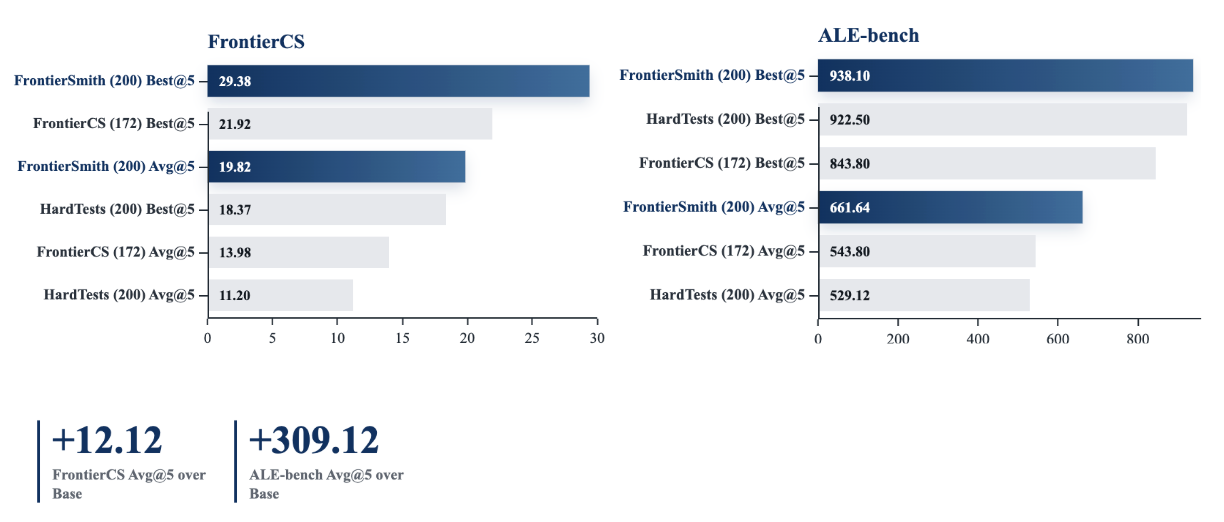
For Qwen3.5-9B, the base model scores 1.80 Avg@5 on FrontierCS. Training on FrontierSmith raises this to 10.62. On ALE-bench, it improves from 327.22 to 633.58. This is close to the 11.17 FrontierCS score from human-curated FrontierCS training, and it beats FrontierCS training on ALE-bench, where the FrontierCS-trained model reaches 558.49.
For Qwen3.5-27B, the effect is stronger. FrontierSmith improves FrontierCS from 7.70 to 19.82, and ALE-bench from 352.52 to 661.64. In this setting, FrontierSmith beats the human-curated FrontierCS training baseline on both benchmarks.
Qwen3.5-27B trained on FrontierSmith achieves the best Avg@5 and Best@5 results on FrontierCS and ALE-bench among the compared training sources.
The closed-ended control is important. HardTests is the seed corpus used by FrontierSmith. Training directly on those closed-ended problems reaches only 5.38 on FrontierCS and 397.18 on ALE-bench for Qwen3.5-9B, far below FrontierSmith’s 10.62 and 633.58. The gain comes from turning closed-ended tasks into open-ended optimization problems, rather than from generic coding RL.
Random reward also fails: FrontierCS reaches only 3.04 and ALE-bench 376.82. This suggests the improvement comes from meaningful open-ended reward signals, rather than exposure to the task format or RL dynamics alone.
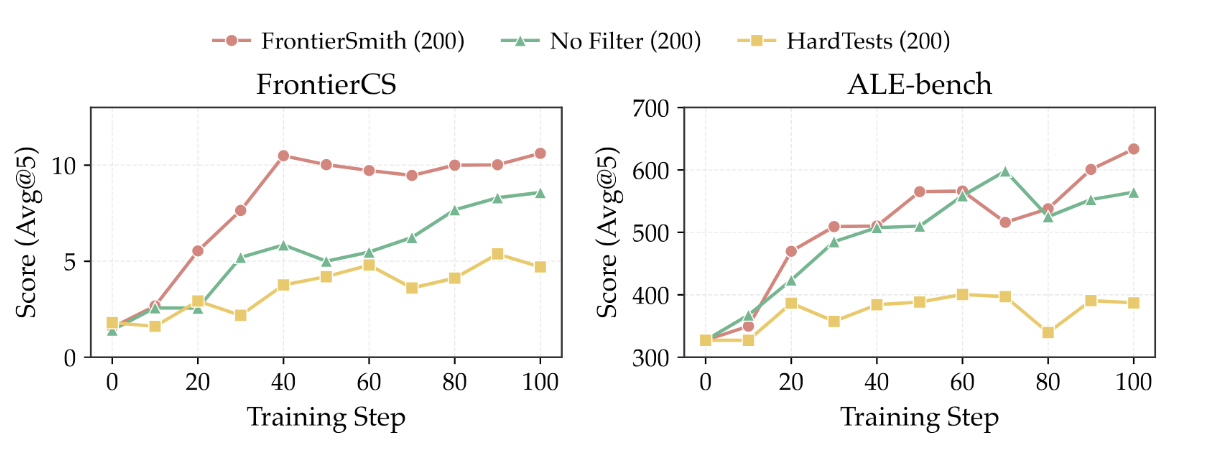
We also test the filtering step. If we skip FrontierSmith’s filters and directly build training environments from mutated problems, performance drops: FrontierCS falls from 10.62 to 8.57, and ALE-bench from 633.6 to 564.4. The idea-divergence filter removes candidates that look open-ended but collapse to narrow solution spaces.
Filtering improves both in-domain FrontierCS performance and cross-benchmark ALE-bench generalization.
Finally, we check whether FrontierSmith tasks actually induce long-horizon agent behavior. We run Claude SDK with Sonnet 4.6, Codex with GPT-5.5, and Kimi Code with K2.6 on FrontierCS, FrontierSmith, HardTests, and ALE-bench.
FrontierSmith behaves like a real open-ended source. Claude SDK reaches 113 turns and 6.3M tokens on FrontierSmith, entering the same long-horizon regime as ALE-bench. HardTests stays short-horizon, and FrontierCS is shorter in this particular experiment.
FrontierSmith problems show strong solution-space diversity and elicit long-horizon behavior from modern code agents.
What We Are Releasing
FrontierSmith gives us a practical scaling path. We do not need to wait for human experts to hand-write thousands of open-ended tasks. We also do not need to pretend that LLMs can invent high-quality industrial optimization problems from nothing. We can start from the large closed-ended coding corpus that already exists, then systematically convert it into trainable, evaluable, continuously scored open-ended optimization data.
This is one step toward the data infrastructure we need for long-horizon coding agents: tasks with no single final answer, continuous feedback, meaningful exploration, and enough scale to train on.
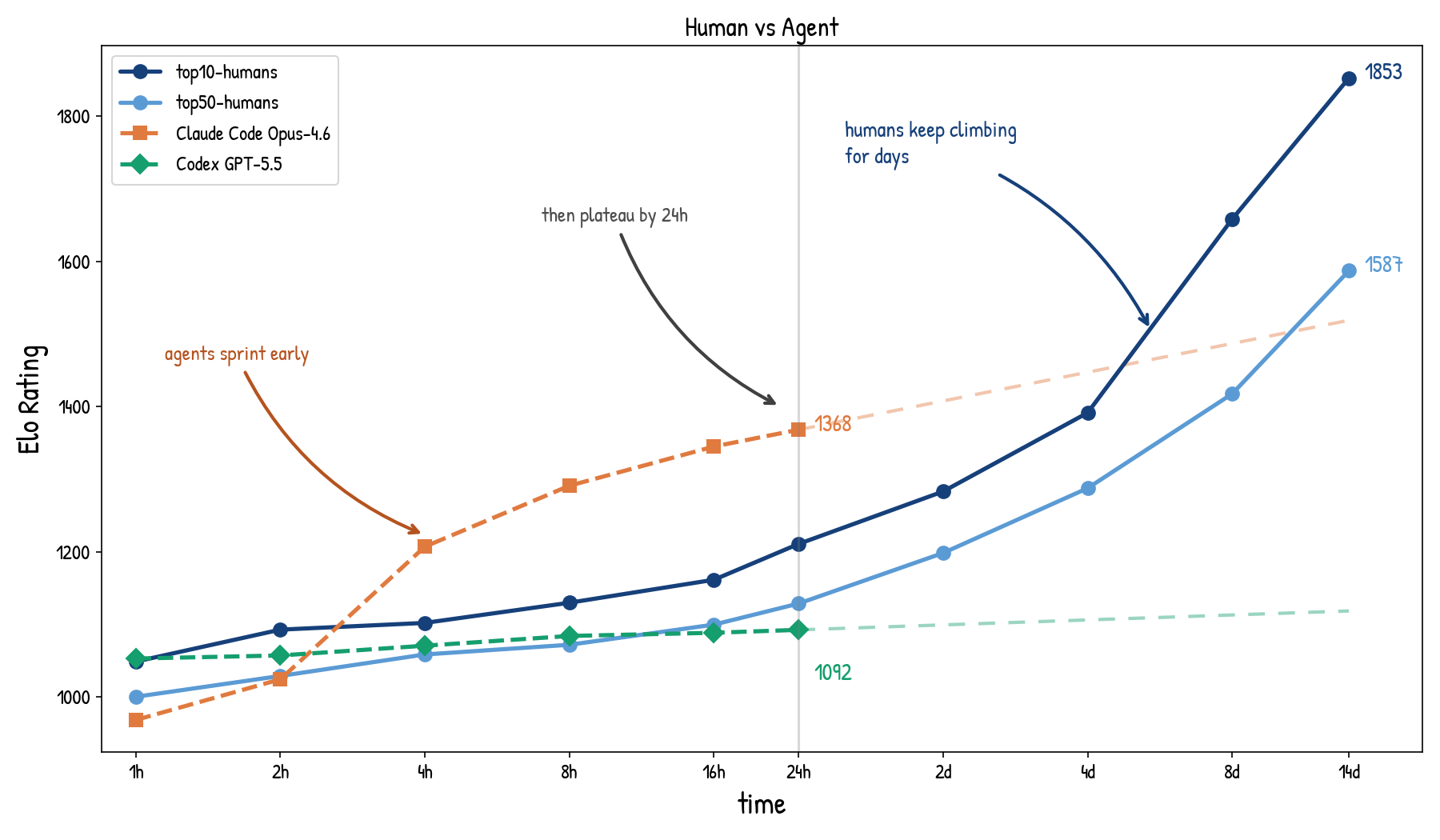
Agents can spend test-time compute by trying, observing, and revising. We derive an Elo reference for repeated sampling, then show that in a 2022 two-week coding marathon, current agents plateau within 24 hours while top humans keep improving.
We integrate FrontierCS into Harbor and release a preview long-horizon agent leaderboard on 178 open-ended algorithmic tasks. Kimi K2.6 and Claude Code Opus 4.7 show similar headline capability, but very different failure modes.