Evaluating Evolving Agent Systems at Scale with Frontier-CS
Evolving agent systems are advancing fast, but evaluation hasn't kept up. We show how Frontier-CS enables comprehensive, large-scale benchmarking of evolving agents—moving beyond small case studies for comparison at scale.
Evolving Agents Are the Next Frontier for LLMs
Evolving agent systems—including methods based on continual learning, memory evolution, and context refinement—are emerging as a promising path toward agents that improve through experience rather than relying on a fixed policy. This matters especially in discovery-style settings, where the agent must learn from prior failures, accumulate useful knowledge, and adapt its future behavior over long horizons. Recent work such as GEPA and ACE (Agentic Context Evolution), SkyDiscover reflects this trend.
A Promising Direction, Bottlenecked by Evaluation
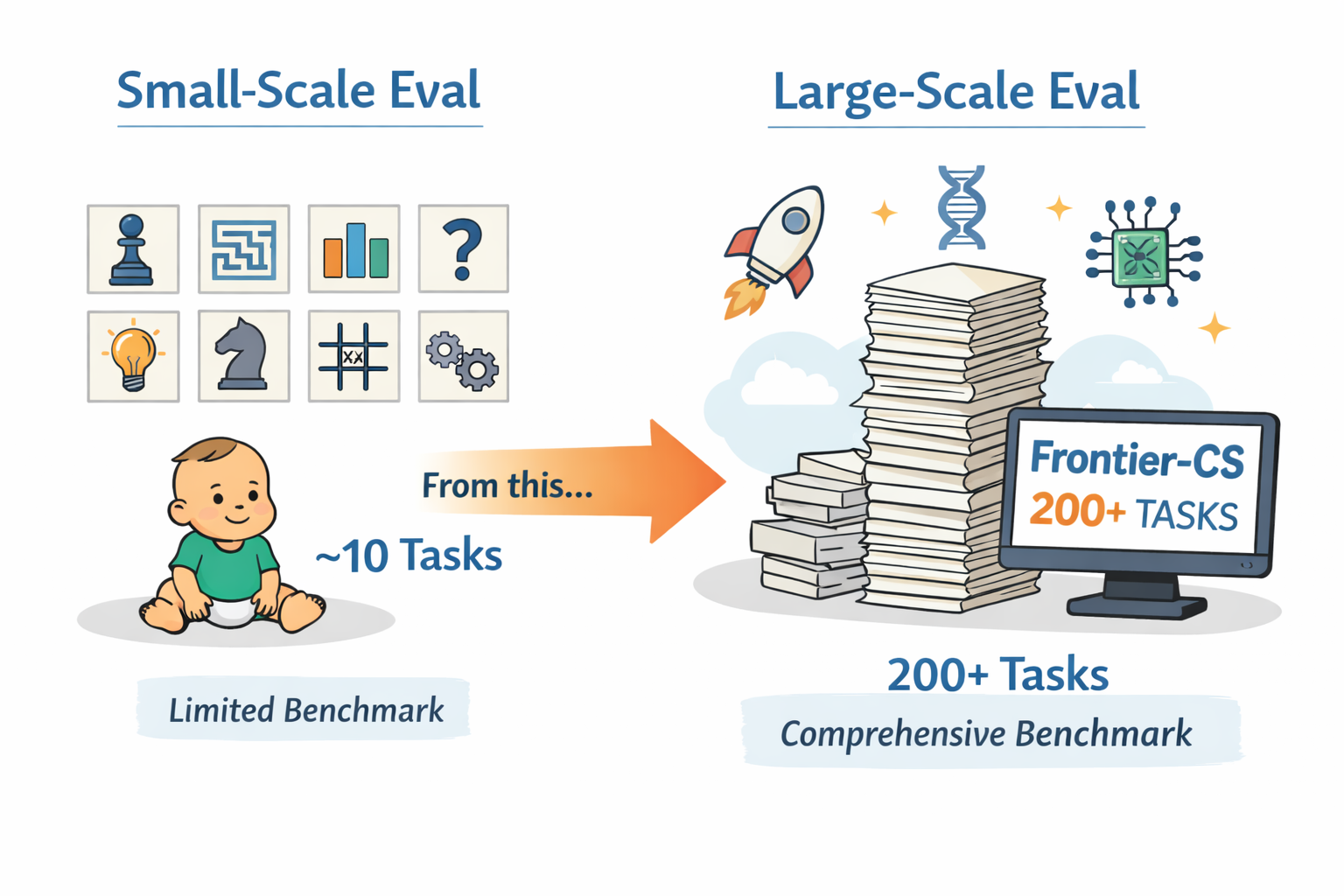
However, evaluation has not kept up. Most prior work demonstrates gains on only ~10 tasks, often selected case studies or small benchmark subsets. That is a weak test for evolving systems: improvement on three or four tasks does not tell us whether a method can generalize across a broad task distribution, remain stable over many iterations, or handle the kinds of long-horizon, high-difficulty reasoning that make evolution necessary in the first place.
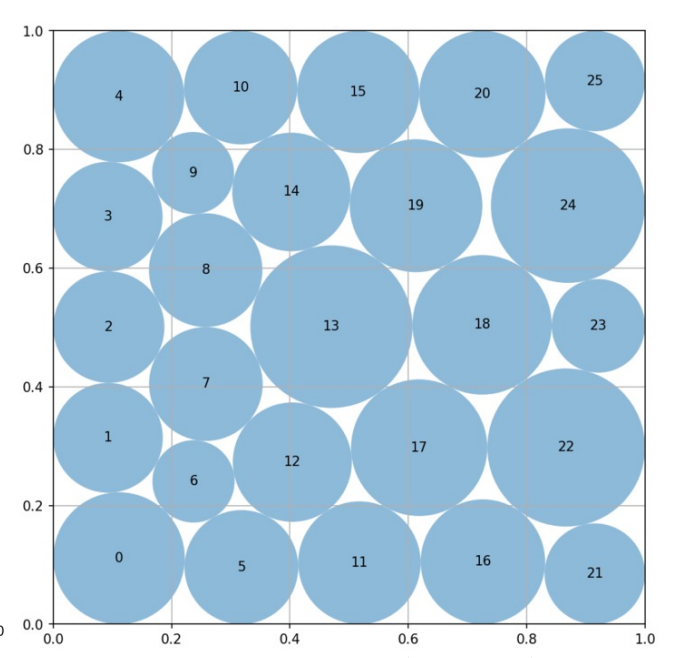
Worse still, many tasks used in prior evolving-agent papers are not expert-crafted and saturate far too quickly. As a result, they fail to measure continued progress in the domain. Circle packing is a telling example: ThetaEvolve, TTT-Discover, AdaEvolve, and EvoX all converge to essentially the same value, 2.635983. Once multiple methods collapse to the same endpoint, the benchmark no longer measures open-ended improvement—it only measures how fast a system reaches saturation.
Existing LLM evolving work converges to the same best for the circle-packing task.
Why Current Evaluation Fails?
We identify two core failure reasons. First, many existing tasks are community-contributed and community-maintained, resulting in limited scale and inconsistent quality. Second, many of these tasks do not have enough difficulty or headroom to meaningfully measure continued progress. Their search spaces are often too small.
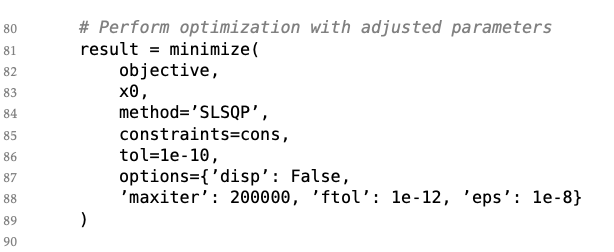
Circle packing is a representative case: the core solution is typically just a ~100-line Python program, and most methods differ only in how they wrap existing SLSQP-based optimization routines.
The only difference across methods in circle-packing problem is how they construct the initial configuration (cons).
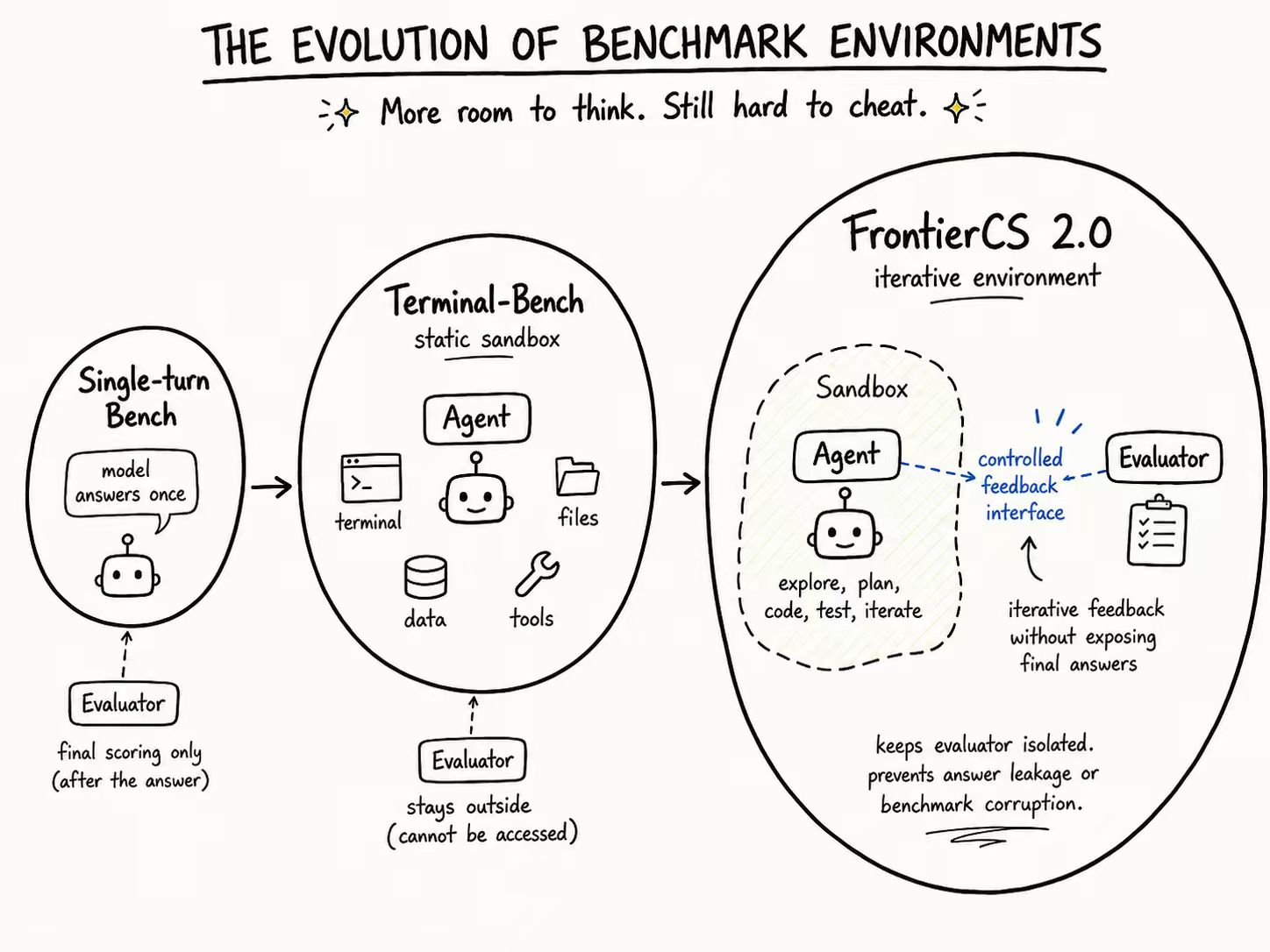
Frontier-CS as the Standard Benchmark for Evolving Agents
Frontier-CS is built to solve exactly the failures of current evaluation. It includes 172 algorithmic tasks and 68 research tasks, all expert-designed by ICPC World Finalists and CS PhDs. That gives it both the scale and the quality consistency missing from small, community-maintained benchmark sets.
Each Frontier-CS task is a distinct, open-ended problem with its own environment, yet still admits deterministic scoring. As a result, Frontier-CS can evaluate evolving agents comprehensively, at scale, and on tasks that are difficult enough to meaningfully measure continued progress.
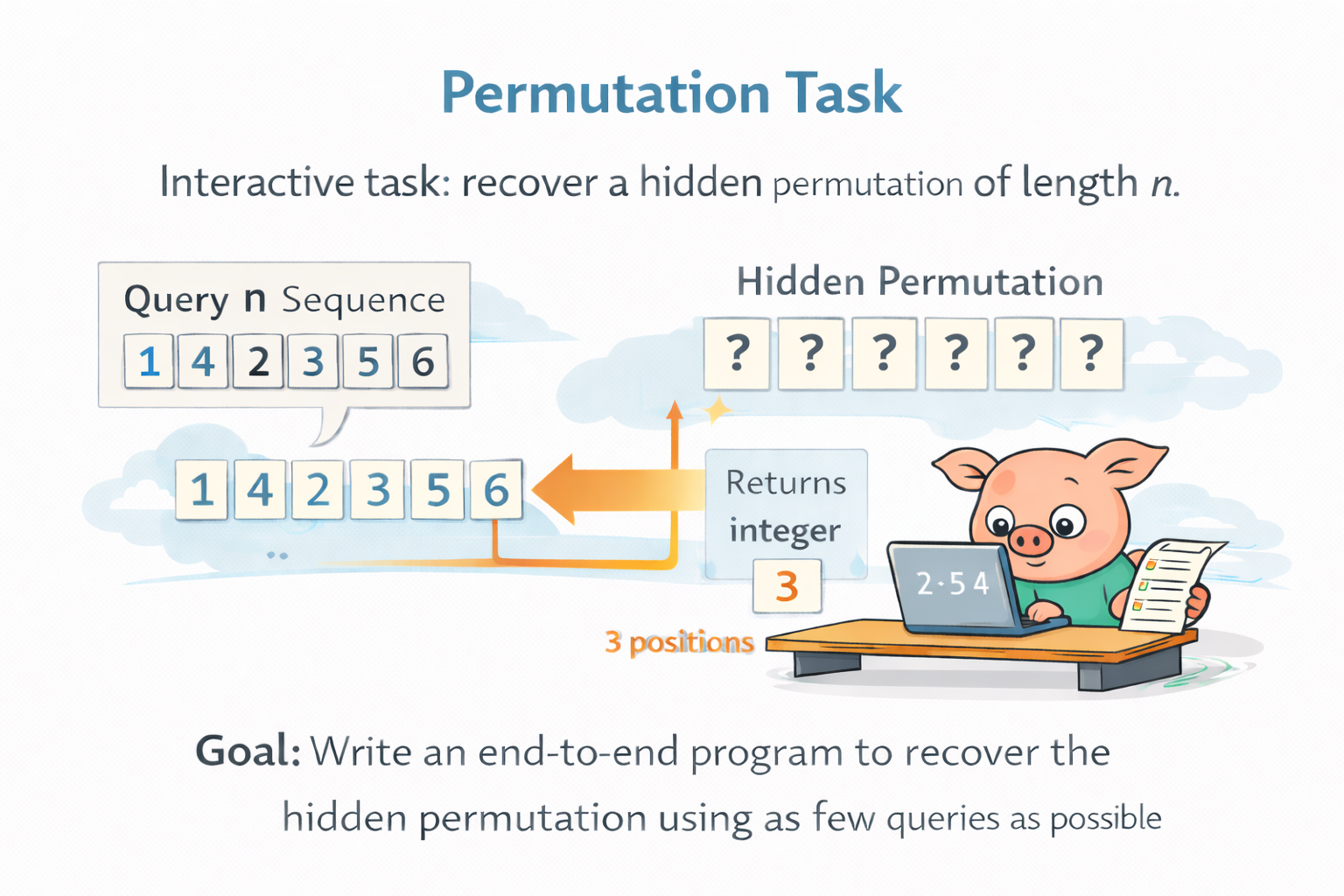
Permutation is a good example of the kind of task Frontier-CS is built around. In this interactive problem, the agent must recover a hidden permutation of length n. In each round, it may propose any length-n sequence over \{1,\dots,n\}, and receives only a single number: how many positions match the hidden target. The objective is to identify the full permutation using as few queries as possible.
What makes this task valuable is not just its combinatorial scale, but the form of interaction itself. The agent has substantial freedom in what to ask, what information to extract from each response, and how to adapt future queries based on past feedback. In other words, the task creates real room for strategy design, information-efficient exploration, and long-horizon reasoning. This is very different from tasks like circle packing, where the search often collapses quickly into a fairly standard optimization problem with limited room for fundamentally different solution strategies. At the same time, Permutation still admits deterministic scoring through query count, enabling clean and scalable comparison across methods.
From Small Case Studies to Comprehensive Evaluation
Frontier-CS is already helping push the field toward real large-scale evaluation. SkyDiscover uses it in a 200+ task benchmark suite, including 172 Frontier-CS programming problems, to compare methods under the same framework, models, and budgets. That is a sharp contrast to earlier evaluations built around only a small handful of tasks. With Frontier-CS, evolving-agent systems can finally be compared comprehensively, fairly, and at scale.
Many discovery problems operate in online evolutionary settings: the system repeatedly proposes solutions, receives feedback, and refines future candidates over long horizons. The key capability here is not just producing good solutions, but learning to improve from experience over time.
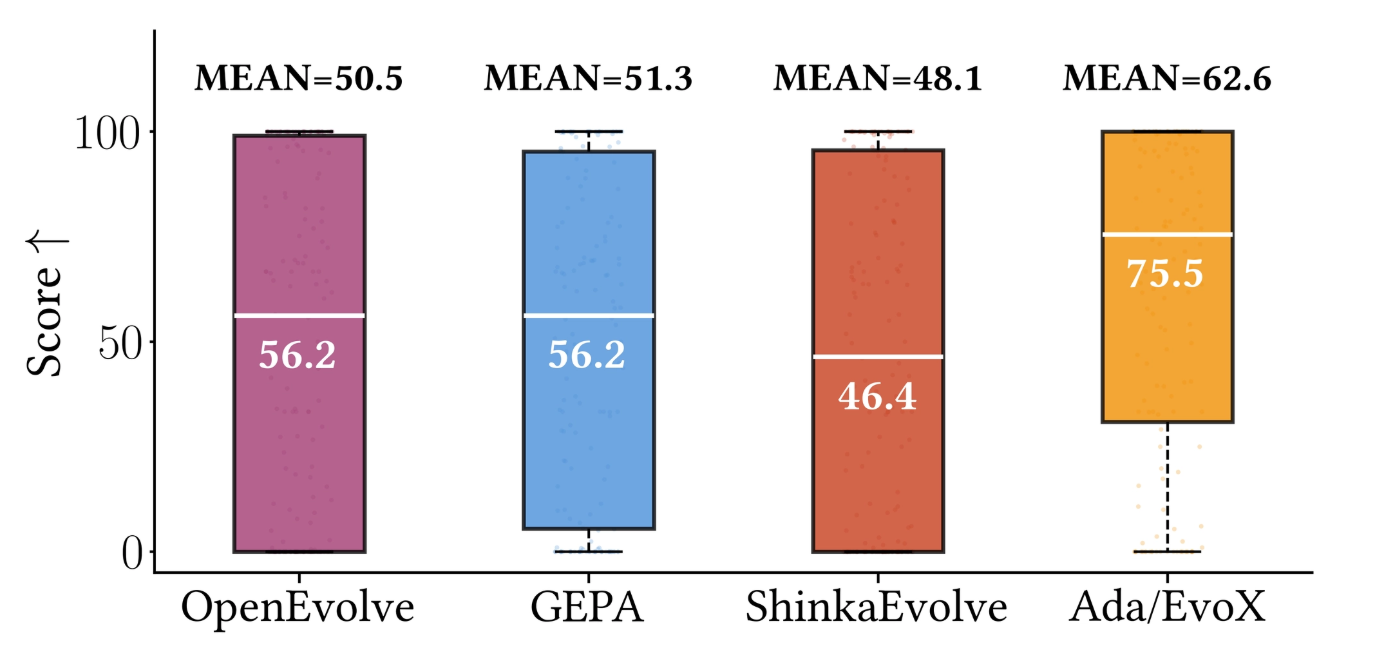
In practice, progress depends heavily on the search strategy—how prior solutions are selected and how new candidates are generated. However, most existing systems (e.g., GEPA, ShinkaEvolve, OpenEvolve) rely on fixed strategies with manually tuned parameters such as explore–exploit ratios or elite selection rules. While these can work well initially, they often stagnate when the search landscape shifts—either across tasks or across different stages of the same optimization.
This motivates adaptive evolutionary algorithms that modify their own search behavior during optimization. SkyDiscover provides a modular framework for implementing such adaptive strategies, including AdaEvolve and EvoX:
AdaEvolve adjusts search intensity and resource allocation based on real-time progress signals.
EvoX goes further—letting the LLM evolve the strategy itself that governs how past experiences are selected and reused.
Across the full Frontier-CS benchmark, adaptive evolution consistently outperforms fixed-strategy methods such as OpenEvolve, GEPA, and ShinkaEvolve. The results highlight that adaptive search becomes increasingly important when evaluating evolving agents at scale, where task diversity and difficulty expose the brittleness of static strategies.
A concrete example illustrates this well. On a polyomino packing task from Frontier-CS, the adaptive algorithm starts from a simple baseline and gradually discovers improved placement strategies—better ordering, symmetry handling, and local compaction—leading to progressively denser layouts over time:
Adaptive evolution progressively discovers denser packing strategies on a polyomino task.
📢 This task is far from saturated. A human expert achieves a packing score of 92, while the best current evolving agent reaches only the low 80s—leaving substantial room for improvement. This stands in sharp contrast to benchmarks like circle packing, where all major methods have already converged to the same ceiling. Frontier-CS tasks are designed with deep search spaces and high expert-level ceilings, ensuring they remain meaningful as methods improve. We encourage the community to develop stronger online evolution strategies and push toward—and beyond—the human expert frontier.
The central goal of using ACE offline is to improve an agent by training an evolving context, or we call it playbook, on traces from previous agent runs. Instead of updating model weights, ACE updates the agent’s context through three stages: the Generator attempts to solve problems, the Reflector extracts useful lessons from successes and failures, and the Curator merges these lessons into a structured playbook. Over time, the playbook accumulates reusable strategies, common mistakes, and code patterns that can be transferred to unseen tasks. This follows the central ACE design principle that contexts should function as evolving playbooks rather than short static prompts.
In the offline setting, this adaptation occurs entirely on the training split. In our experiments, the dataset contains 120 training problems, 25 validation problems, and 27 test problems. The validation set is used to select the best playbook checkpoint during training, and the selected best playbook is then evaluated on held-out test problems. Intuitively, offline ACE resembles studying from a growing notebook before an exam: the model’s parameters remain unchanged, but it enters evaluation equipped with a richer collection of structured strategies.
During offline training, ACE continuously expands its playbook of strategies. These entries are stored as structured bullets such as strategies, heuristics, code templates, and common mistakes. This playbook corresponds to the evolving context memory described in ACE, where knowledge accumulates through repeated cycles of generation, reflection, and curation.
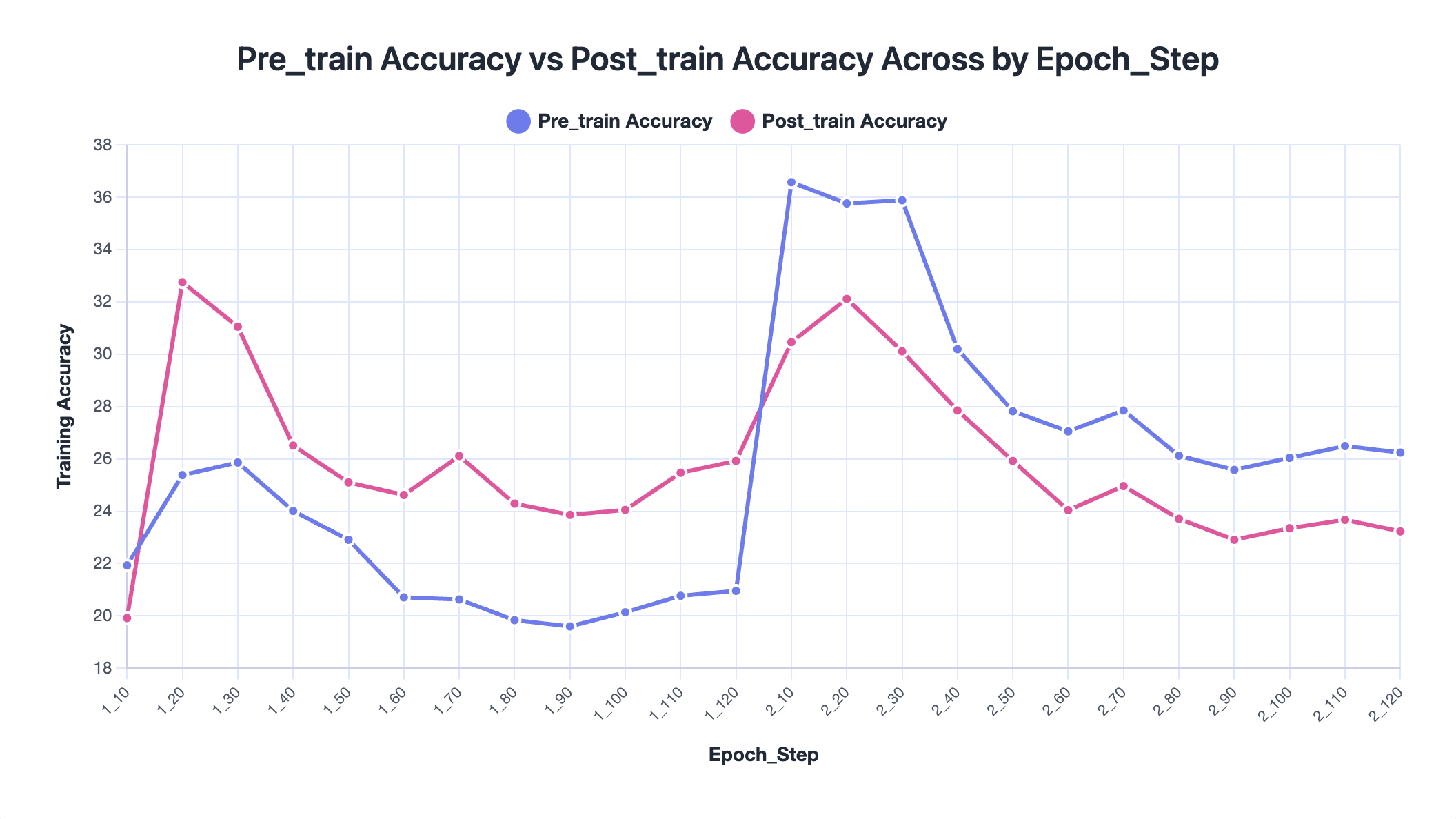
Over the course of training, the playbook grows substantially—from roughly 2k tokens to about 62k tokens. However, the best-performing checkpoint occurs when the playbook is around 20k tokens, suggesting that larger contexts do not necessarily lead to better performance. Moreover, most of the content of playbook is relatively specific, only around 13 out of 110 could be applied generally. Aggressive accumulation may introduce redundancy or noise that weakens the usefulness of the stored knowledge.
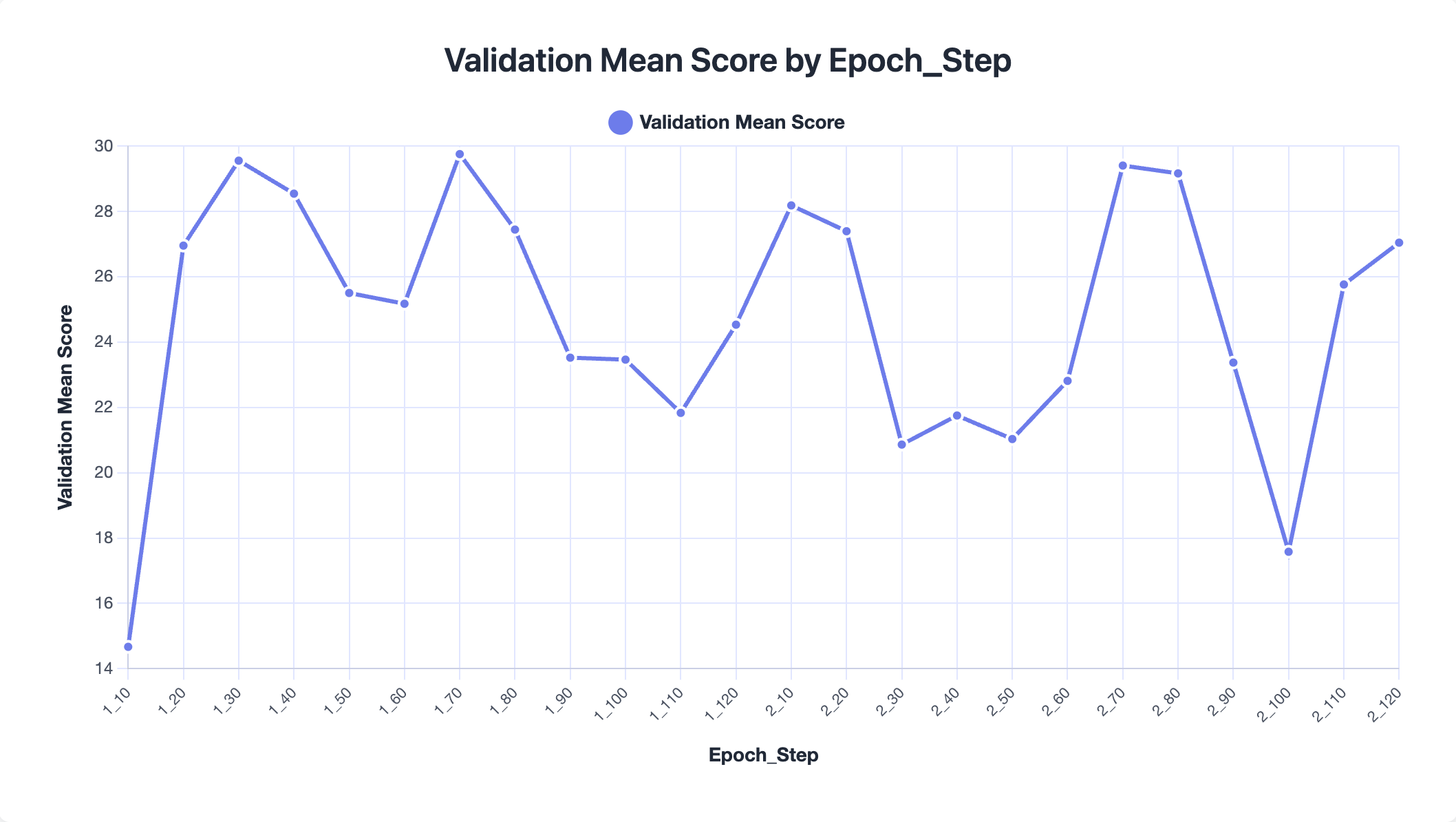
We observe that the best performance occurs at epoch 1, step 70, after which training begins to degrade. In some cases, the no-training accuracy is actually higher than the trained accuracy, indicating that the playbook may start to overfit the training tasks. Overall improvements remain relatively modest (around 2% on average), suggesting that extremely large playbooks can dilute useful signals. In practice, pruning or filtering low-value entries may help maintain a more effective context.
Validation mean score over training steps. The best checkpoint occurs early, after which performance plateaus.Training accuracy before and after each playbook update, cumulated by epoch. Post-train accuracy often falls below pre-train, suggesting overfitting.
Our offline results suggest that the main bottleneck is not simply how much knowledge the playbook stores, but what kind of knowledge it stores and how that knowledge is used.
First, many playbook entries are too task-specific, capturing narrow solution details rather than reusable strategies. Future work may need stronger abstraction mechanisms that distill concrete experiences into higher-level algorithmic principles that transfer across tasks.
Second, as the playbook grows, performance does not necessarily improve. In our experiments, the playbook expands from roughly 2k tokens to 62k tokens, but the best-performing checkpoint occurs around 20k tokens. This suggests that context evolution should focus on selective accumulation rather than simply growing larger contexts.
Finally, a key limitation is weak credit assignment. Because the model outputs only code, it is difficult to determine which playbook entries actually contributed to a solution. Future systems may benefit from better attribution or retrieval mechanisms that track which strategies are used and activate only the most relevant knowledge for each task.
This experiment highlights that Frontier-CS can serve as a useful feedback platform for evolving agents to measure their performance and continuously improve the design to achieve better quality in the future.
📢 Overall, these results suggest that the next generation of evolving-agent systems may depend less on building larger playbooks and more on learning how to construct more structured, reusable, and selectively activated knowledge. Many discovery problems operate in online evolutionary settings: the system repeatedly proposes solutions, receives feedback, and refines future candidates over long horizons. The key capability here is not just producing good solutions, but learning to improve from experience over time.
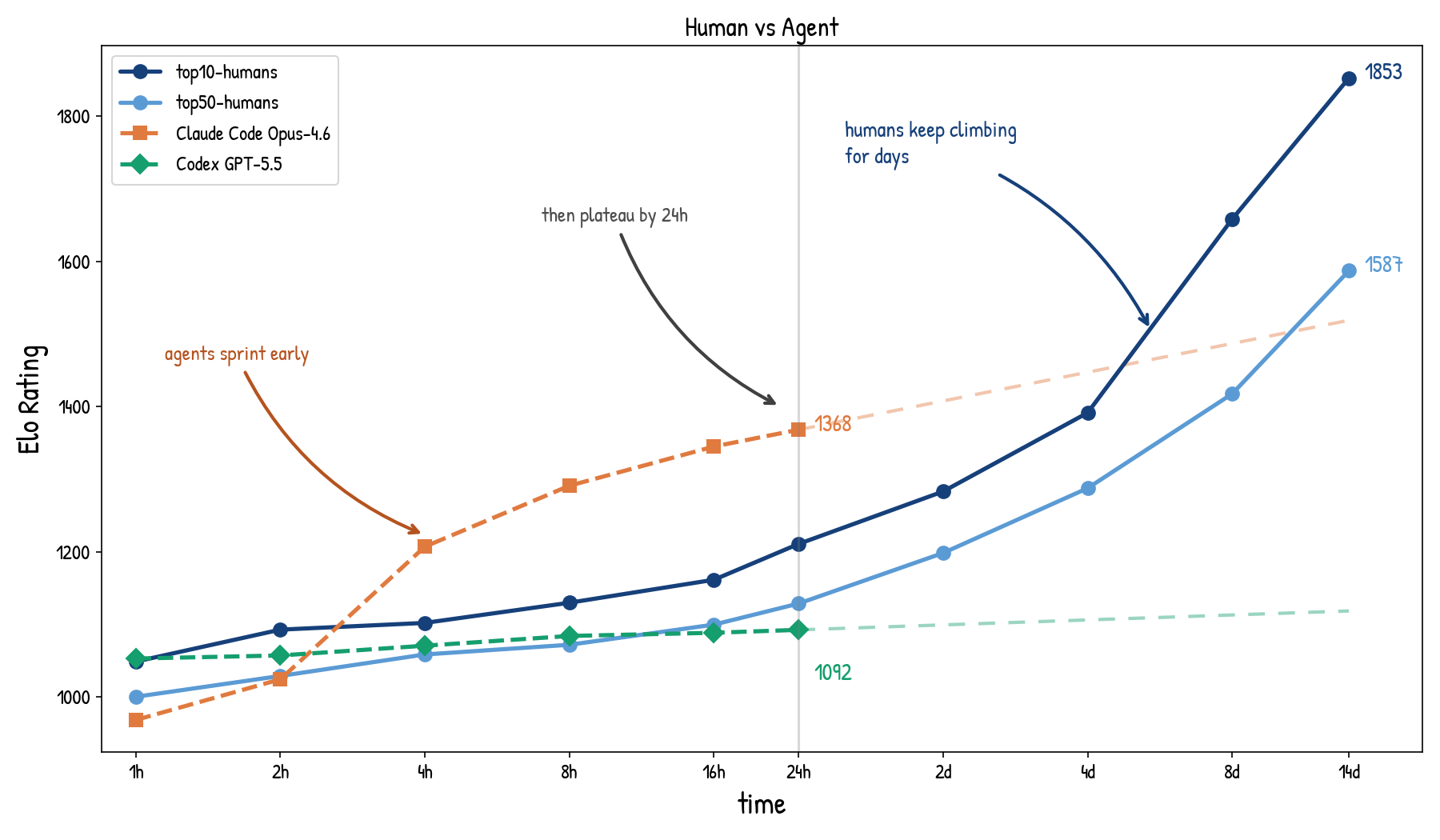
Agents can spend test-time compute by trying, observing, and revising. We derive an Elo reference for repeated sampling, then show that in a 2022 two-week coding marathon, current agents plateau within 24 hours while top humans keep improving.
We release FrontierSmith, a system that converts closed-ended coding problems into open-ended optimization tasks for training long-horizon coding agents.