TL;DR: FrontierCS 1.0 rethought problem and score, moving benchmarks from closed-ended exam tasks toward open-ended research tasks, or what to solve; FrontierCS 2.0 rethinks environment and scope, or how to solve.
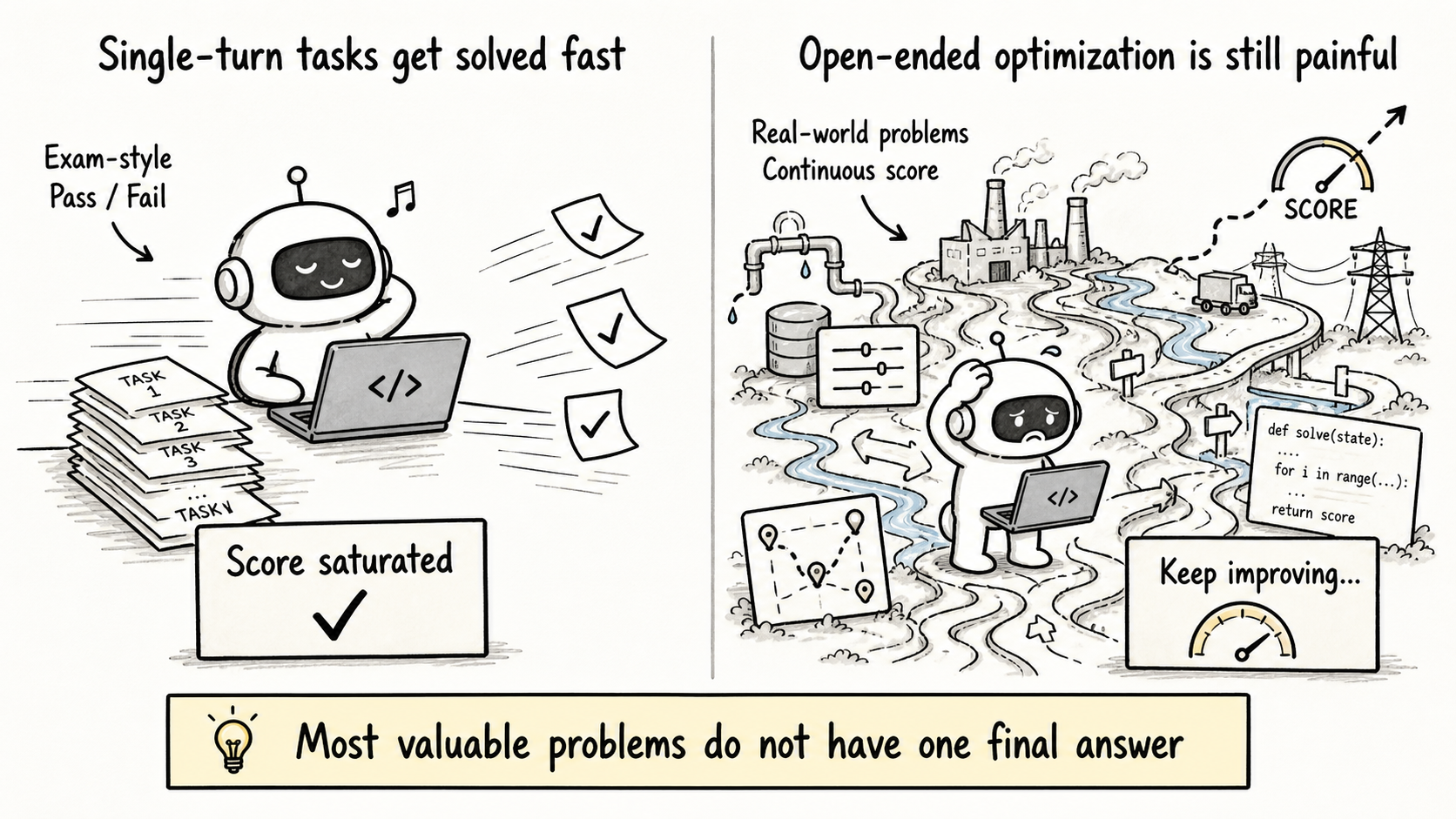
FrontierCS 1.0 made two bets: open-ended problems and continuous scoring. Those bets still look right. Frontier models are strong on exam-style tasks, but open-ended research and engineering tasks still expose a different failure mode: agents often know many local moves, but struggle to keep improving.
FrontierCS 2.0 makes the next two bets: feedback-driven environments and repo-level scope.
What’s New in FrontierCS 2.0
This FrontierCS 2.0 update includes four changes.
Agent-native tasks
FrontierCS 1.0 algorithmic tasks now run as containerized Harbor-compatible tasks.
Released private tests
We are releasing the private test cases for FrontierCS 1.0 algorithmic tasks.
Controlled feedback
Agents can receive evaluator feedback during execution without direct evaluator access; GPU-backed tasks can run through Modal.
Repo-level previews
We are releasing 10 preview tasks for richer repo-level open-ended work.
The short version is simple: open-ended evaluation remains the core idea. FrontierCS 2.0 changes the environment around it.
The Feedback Loop in Three Settings
The same evaluation pattern appears in settings that are easy to see: the agent proposes an artifact, receives feedback, and improves it over time.
Polyomino Packing. Codex + GPT-5.5 improves a fixed square-ish case from roughly 63.7 to 82.5 using record-high submissions.
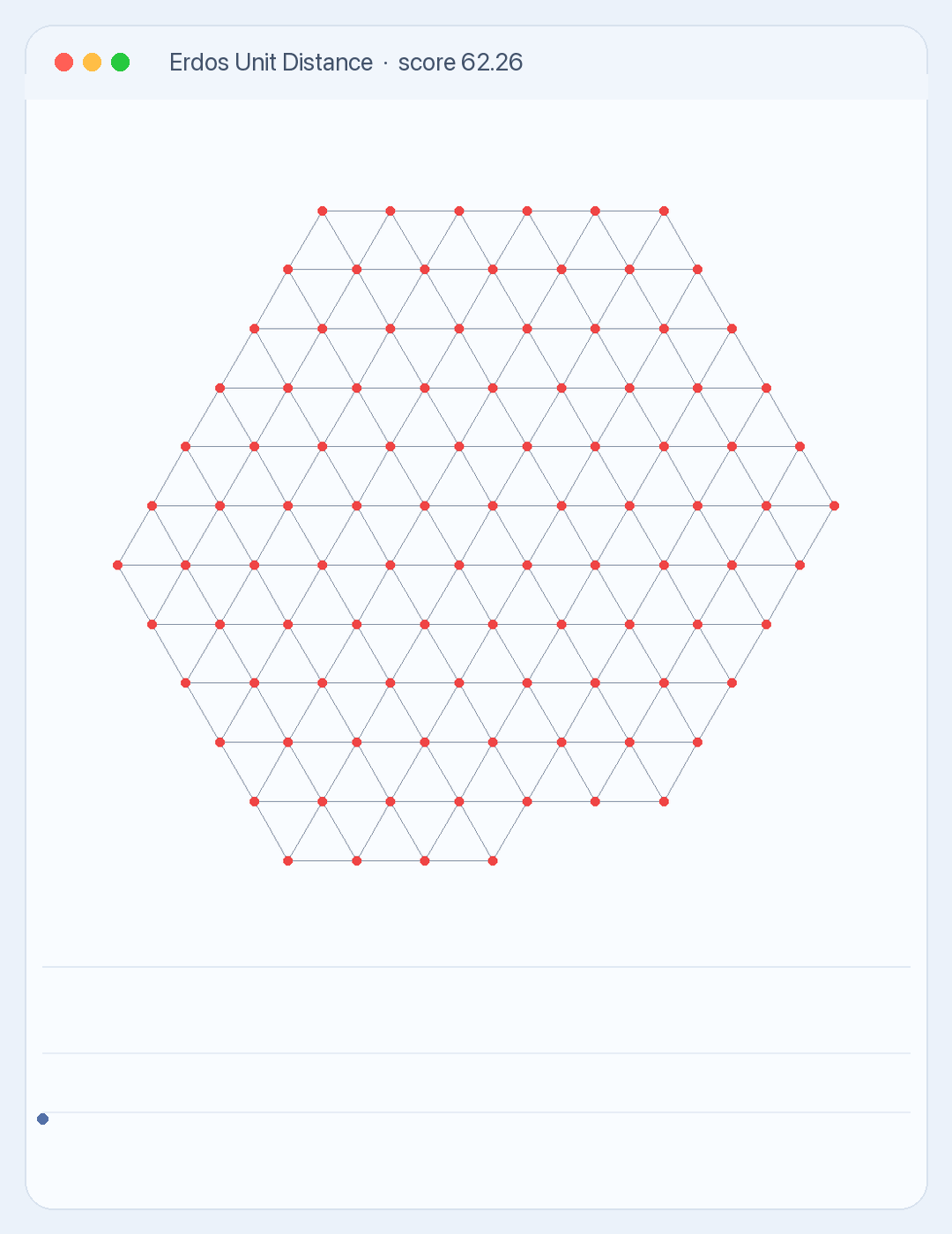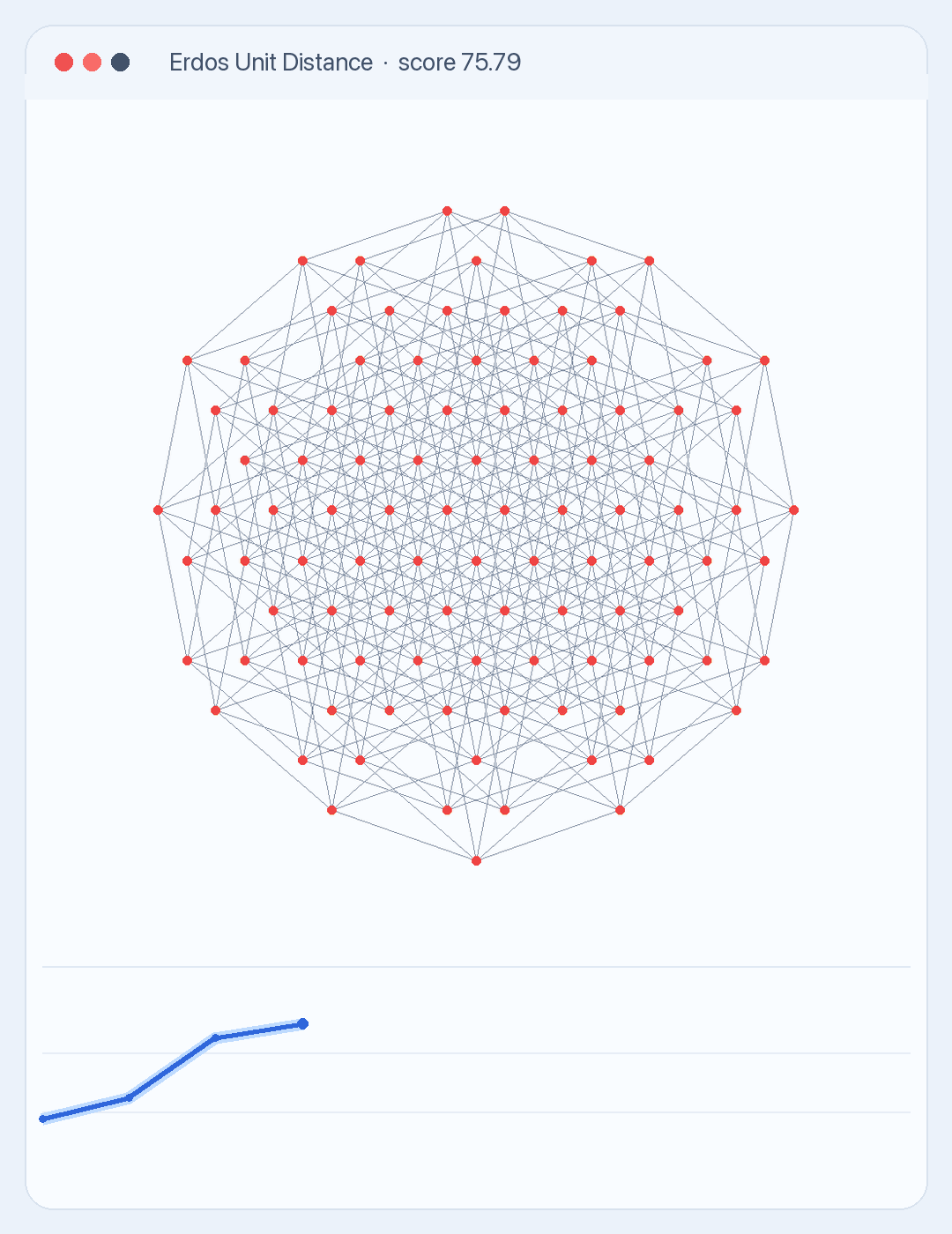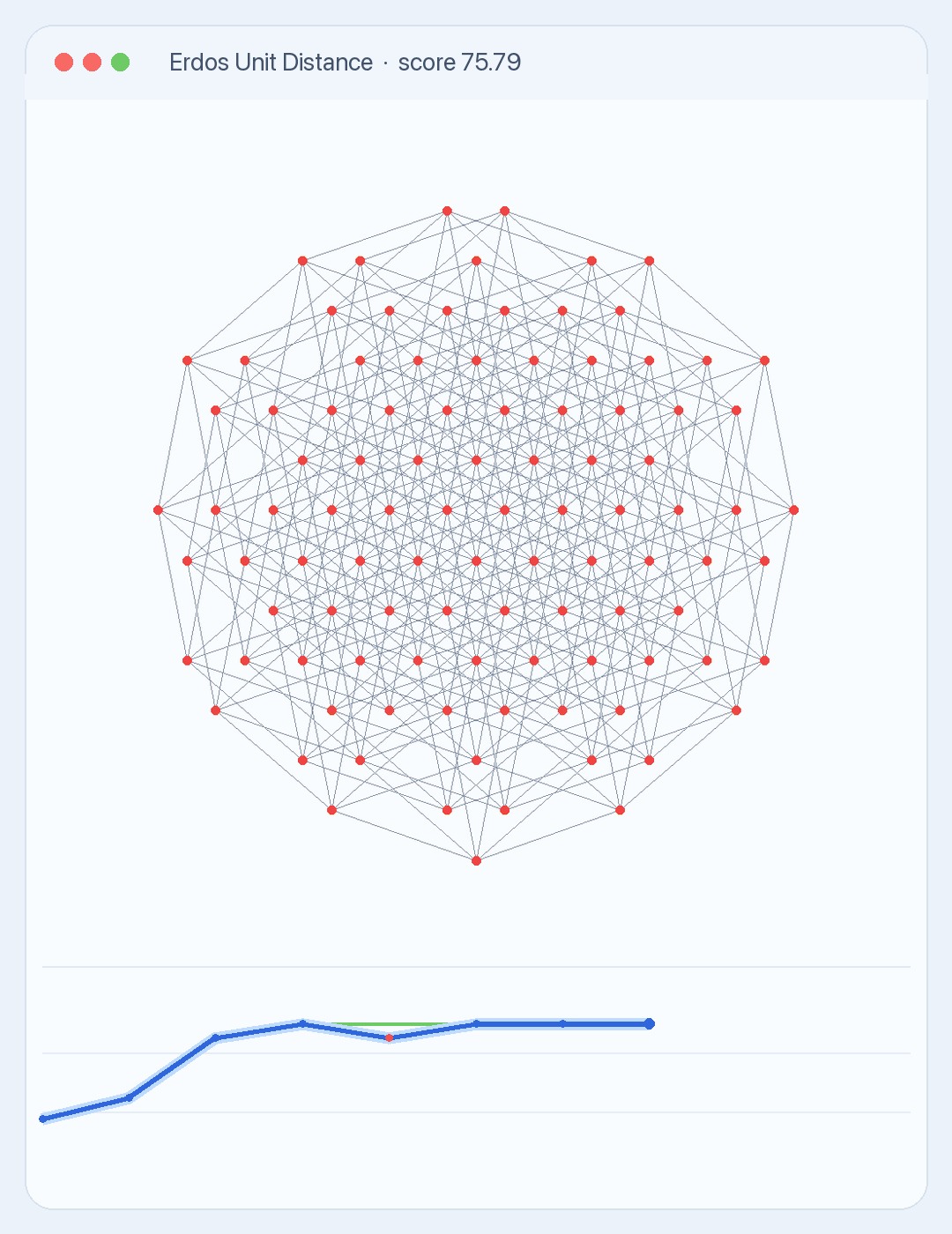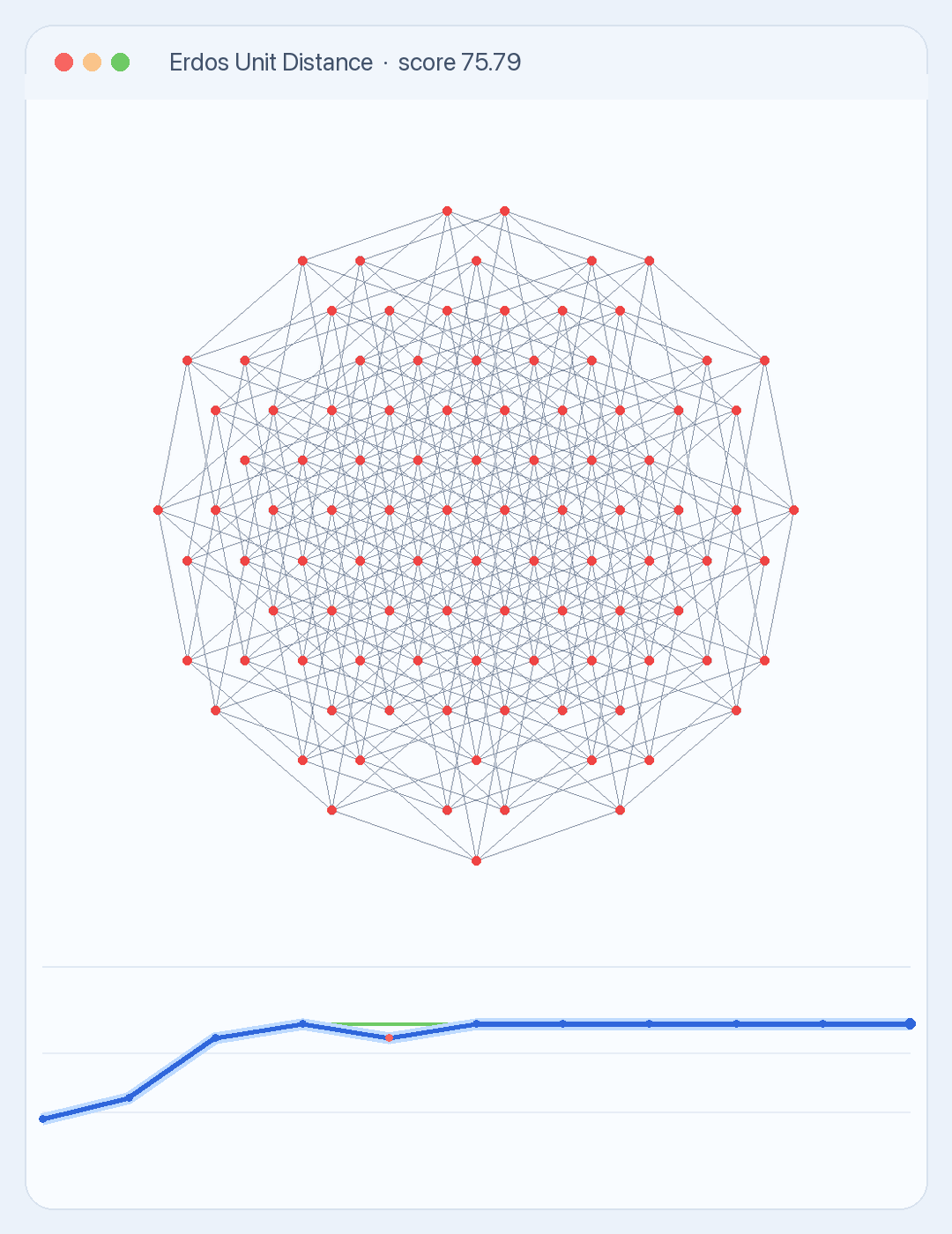
Erdős Unit Distance. A small 100-point visual task where the agent searches for better geometric constructions under a measurable objective.
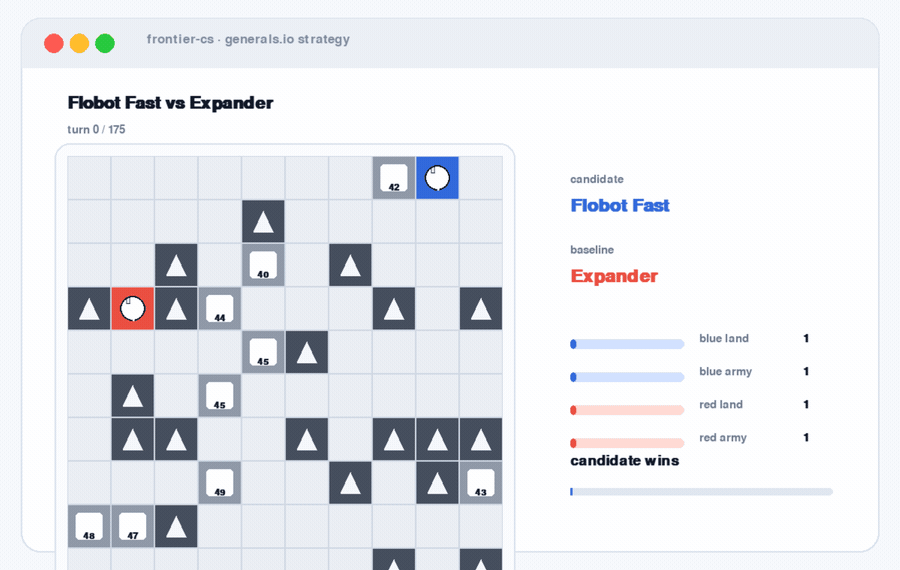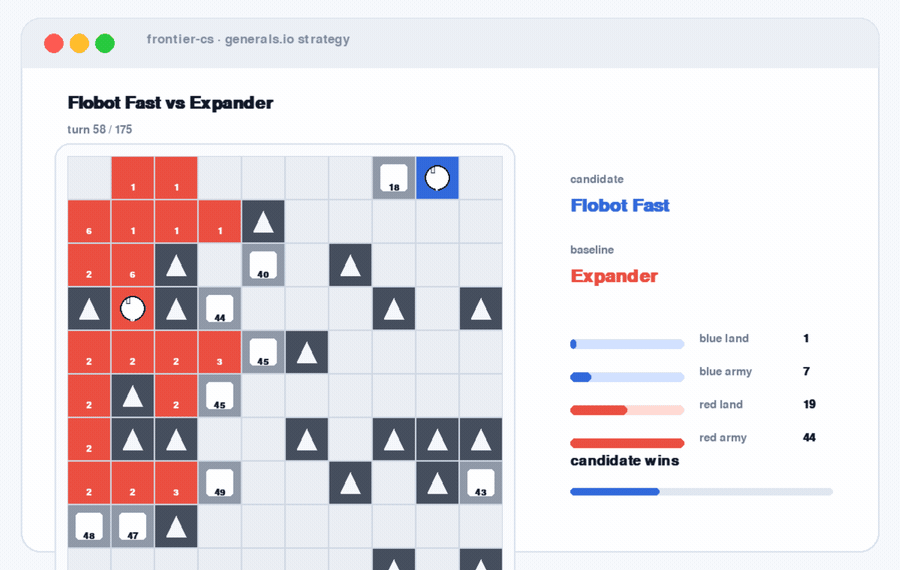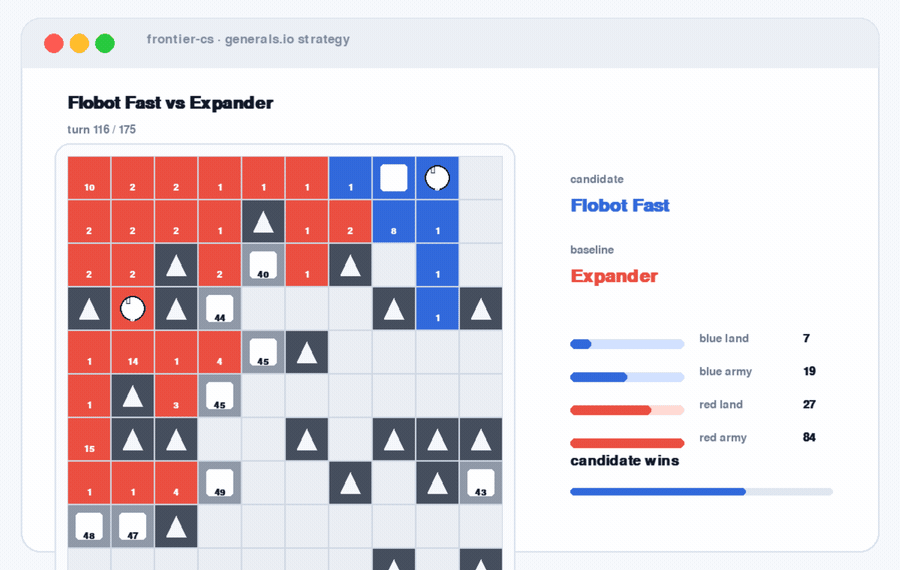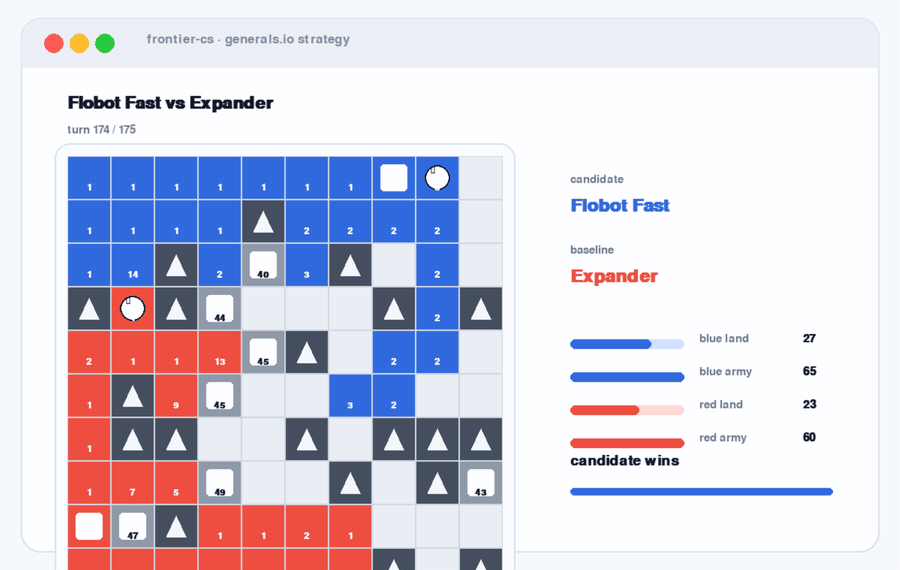
Generals.io Strategy. A dynamic replay where the artifact is not a static solution, but a policy playing out over time.
These settings have different artifacts. A packing layout. A geometric construction. A game strategy. A database patch. A serving scheduler. The common structure is the same: the agent needs to try, measure, revise, and keep improving.
Why This Direction
The next generation of agent evaluation should not only ask whether a model can answer harder questions. It should ask whether an agent can make sustained progress in an environment.
This is becoming more visible in frontier research. OpenAI’s recent Erdős unit distance result put construction-style mathematical discovery in the spotlight. The problem asks how many pairs of points can be exactly one unit apart. OpenAI announced an AI-generated counterexample to a long-standing Erdős unit distance conjecture, and mathematicians later published a human-verified explanation.
The exact maximum remains open. That is the important part. Progress in these settings is not a one-shot answer. It comes from search, construction, verification, and refinement.
That is the type of behavior FrontierCS 2.0 is built to study.
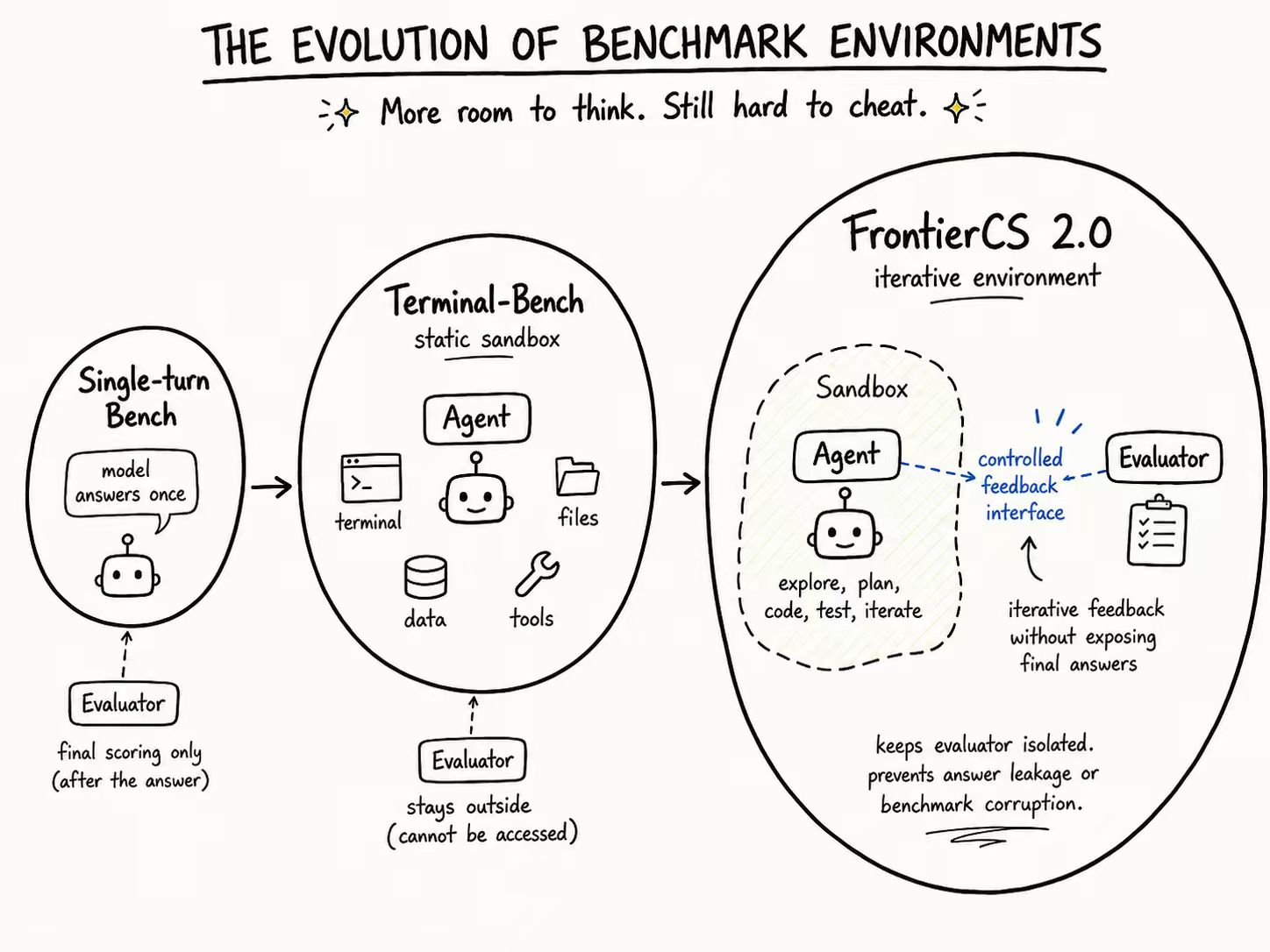
From Static Harbor to Feedback
Our first step was to make the original FrontierCS algorithmic tasks work as Harbor tasks. The agent enters a sandbox, reads the task, works with files and tools, and submits a final solution. This is the static Harbor setting.
Static Harbor is already a large step beyond single-turn prompting. The agent can act inside an environment. But the evaluator still sits outside the run. The agent works, submits, and only then gets scored.
FrontierCS 2.0 builds on Harbor and changes this interface. For open-ended tasks, final-only scoring is often too weak. The agent needs feedback while it is still searching.
The key is control. We do not expose the evaluator directly. We do not leak hidden answers. We do not want agents to optimize against quirks of the scoring script. We want a safe feedback channel: enough signal for iteration, enough isolation to preserve benchmark integrity.
FrontierCS 2.0 builds on the sandbox idea: agents get more room to iterate, while evaluators stay isolated.
What We Mean by Repo-Level
Repo-level does not mean letting an agent edit everything.
It means the repo is part of the task environment. The agent can read real code, understand existing abstractions, build or serve the system, and edit a controlled part of the implementation. The full repo gives context. The patch policy keeps the benchmark fair.
This is the pattern we want:
realistic codebase contextclear task objectiverunnable workflowcontrolled feedback during the runnarrow writable surfacehidden final evaluation
Here are three examples.
DuckDB E2E Query Optimization
Improve analytical query performance while preserving SQL correctness.
Patch surface: optimizer/execution only; no TPC-H hard-coding or environment tricks.
Vector DB ANN
Build a Rust ANN service under fixed API, CPU, memory, recall, and QPS constraints.
Patch surface: hidden vectors and ground truth; must satisfy recall@10 >= 0.95.
vLLM LLM-Serving Optimization
Speed up mini-swe-agent serving while preserving task accuracy, following Continuum.
The vLLM task shows how this control works. The agent is given the full vLLM repo because the optimization requires real systems context. It needs to understand serving, scheduling, batching, KV-cache behavior, and the OpenAI-compatible request path.
The objective is not just to make vLLM faster. The patched server must speed up a mini-swe-agent workload while preserving task-solving accuracy close to the vanilla vLLM baseline. We use accuracy on the downstream agent task as the correctness proxy: a faster server that changes model behavior or hurts task quality should not score well.
We also control where the agent can patch. The intended writable surface is online serving efficiency: request scheduling, batching, prefix or prompt-cache reuse, KV-cache management, preemption, admission control, and nearby scheduler/execution wiring. The evaluator rejects changes to CUDA/C++, build systems, packaging, tests, benchmark files, secrets, model implementations, distributed internals, and benchmark-specific shortcuts.
That is the target shape for FrontierCS 2.0: real systems work, controlled patch surfaces, and feedback loops that reward genuine improvement.
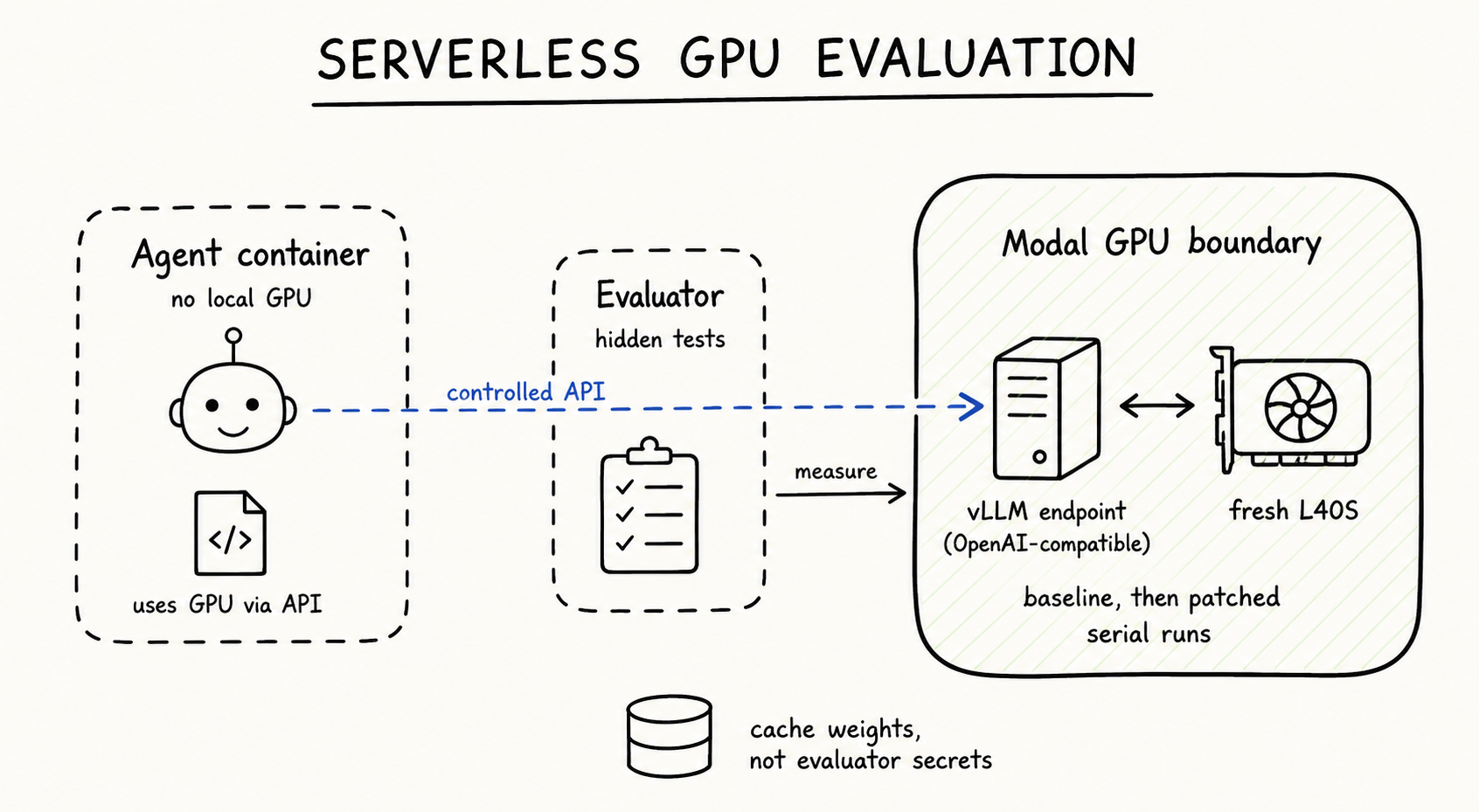
Serverless GPUs as an Evaluation Boundary
Some repo-level tasks need GPUs. That adds another benchmark boundary: even if the agent container and evaluator container are isolated, a shared GPU can still leak state through warm processes, caches, contention, or scheduling noise.
For the vLLM task, we use Modal for that boundary. The agent and judge containers stay CPU-only. The model server runs on an on-demand NVIDIA L40S and exposes an OpenAI-compatible endpoint, so the agent can use the service without owning the GPU.
The agent can use GPU-backed serving through a controlled endpoint, while the GPU itself stays outside the agent container.
Each submitted patch is baked into a Modal image. vLLM precompiled CUDA kernels keep builds fast and enforce the Python-only patch policy. Baseline and patched servers are measured serially on the same GPU class, never concurrently: baseline is measured and cached; the patched server is launched, health-checked, measured, and stopped. Modal volumes cache model weights and vLLM artifacts without exposing hidden evaluator state. The goal is reproducible GPU serving evaluation, not just cheaper hosting.
What We Want Researchers to Try
FrontierCS 2.0 is aimed at frontier labs and agent researchers who care about long-horizon evaluation.
If you build agents, use these tasks to test more than final success. Look at how your agent uses feedback. Does it recover from bad submissions? Does it overfit public signals? Does it keep a useful search state? Does it improve the artifact, or only learn to game the harness?
If you build benchmarks, we think this is the important interface: agents should get enough feedback to make progress, but not enough access to corrupt the evaluator.
Open-ended evaluation was the right direction for FrontierCS 1.0. FrontierCS 2.0 keeps that bet, and moves it into the environment.
FrontierCS 2.0 in one line: more room for agents to search, build, and iterate; still hard to cheat.
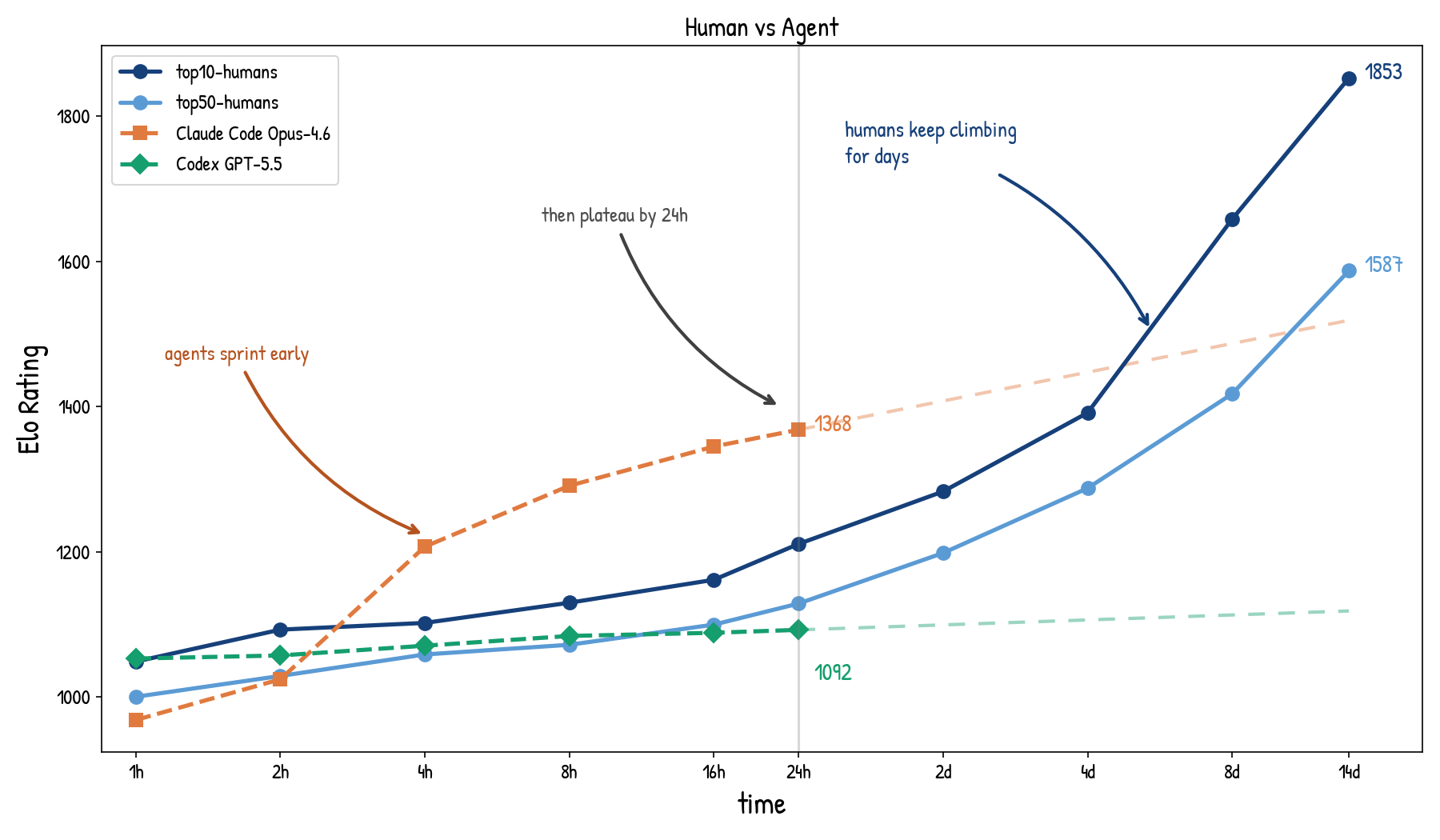
Agents can spend test-time compute by trying, observing, and revising. We derive an Elo reference for repeated sampling, then show that in a 2022 two-week coding marathon, current agents plateau within 24 hours while top humans keep improving.
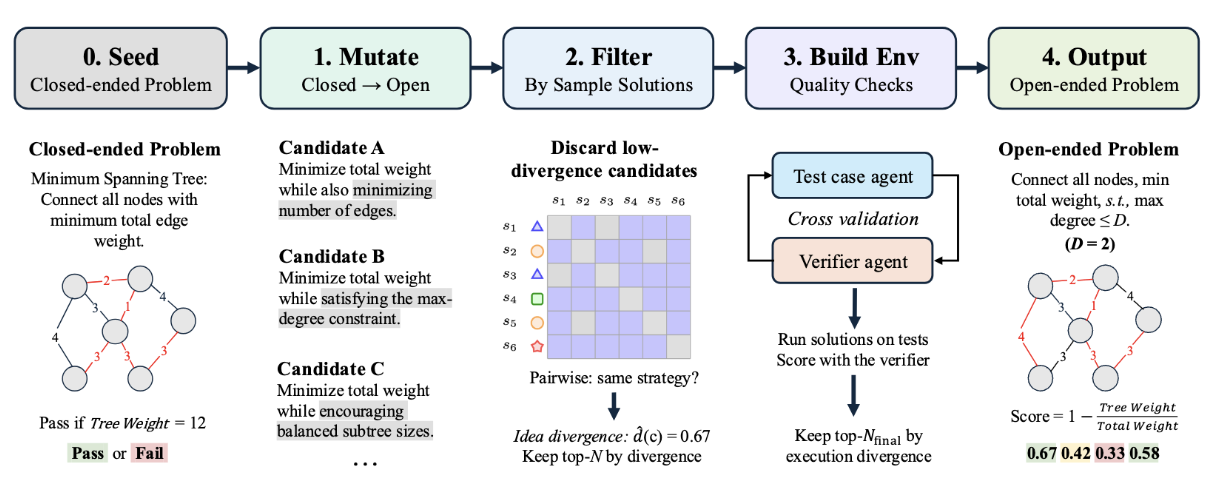
We release FrontierSmith, a system that converts closed-ended coding problems into open-ended optimization tasks for training long-horizon coding agents.
We integrate FrontierCS into Harbor and release a preview long-horizon agent leaderboard on 178 open-ended algorithmic tasks. Kimi K2.6 and Claude Code Opus 4.7 show similar headline capability, but very different failure modes.