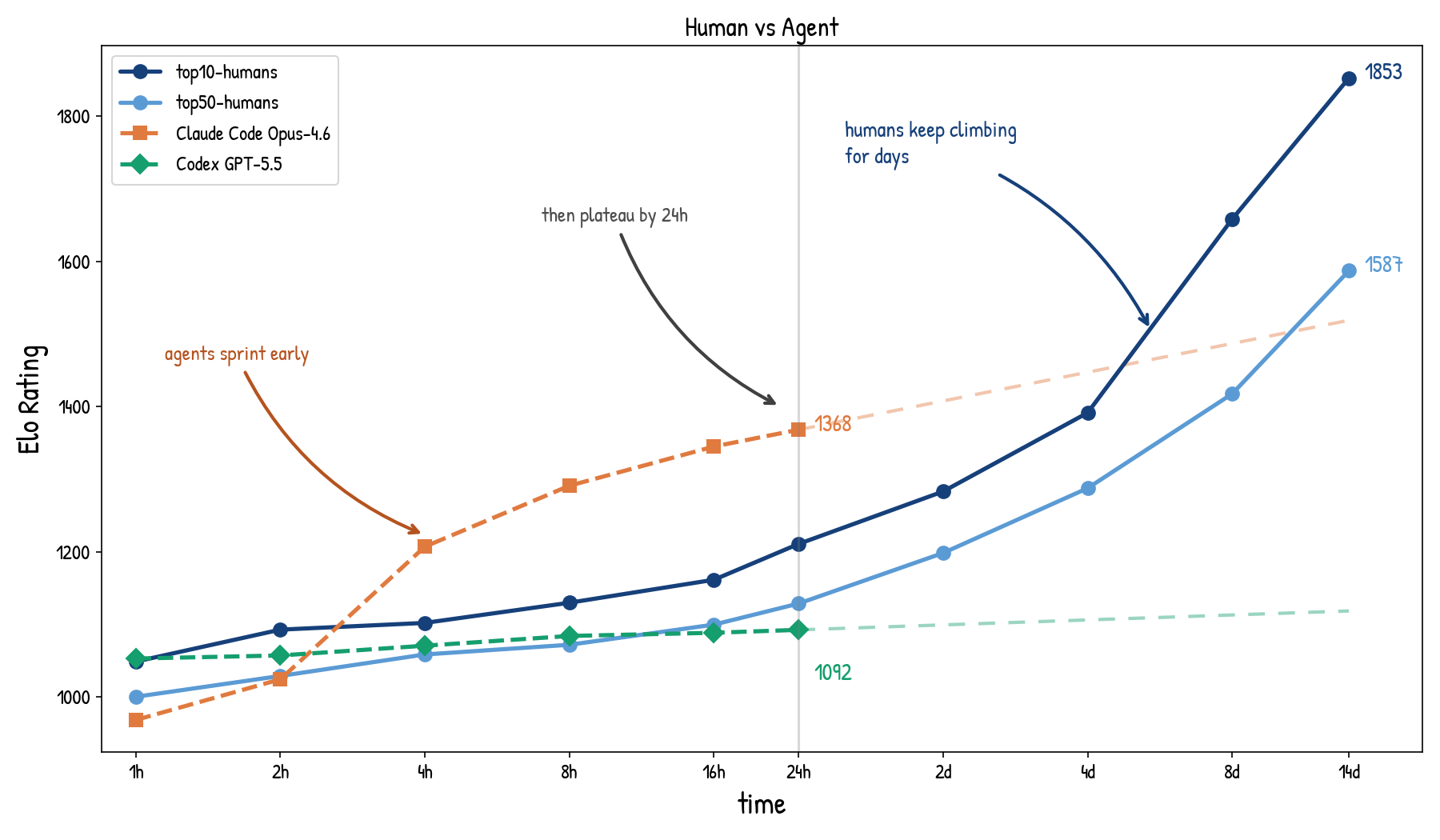
Humans Still Beat AI in the Long Horizon: Revisiting Test-Time Scaling in the Agent Era
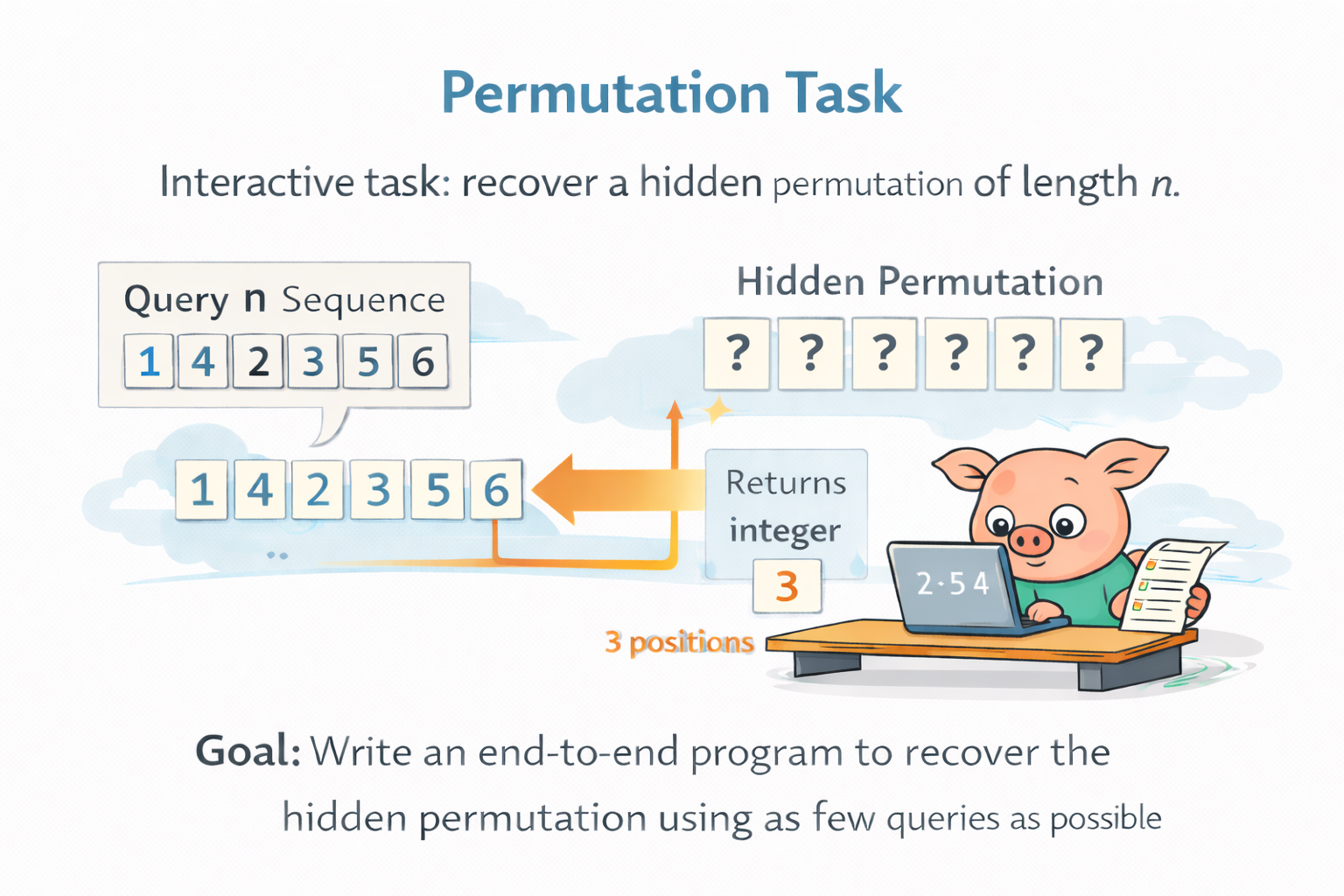
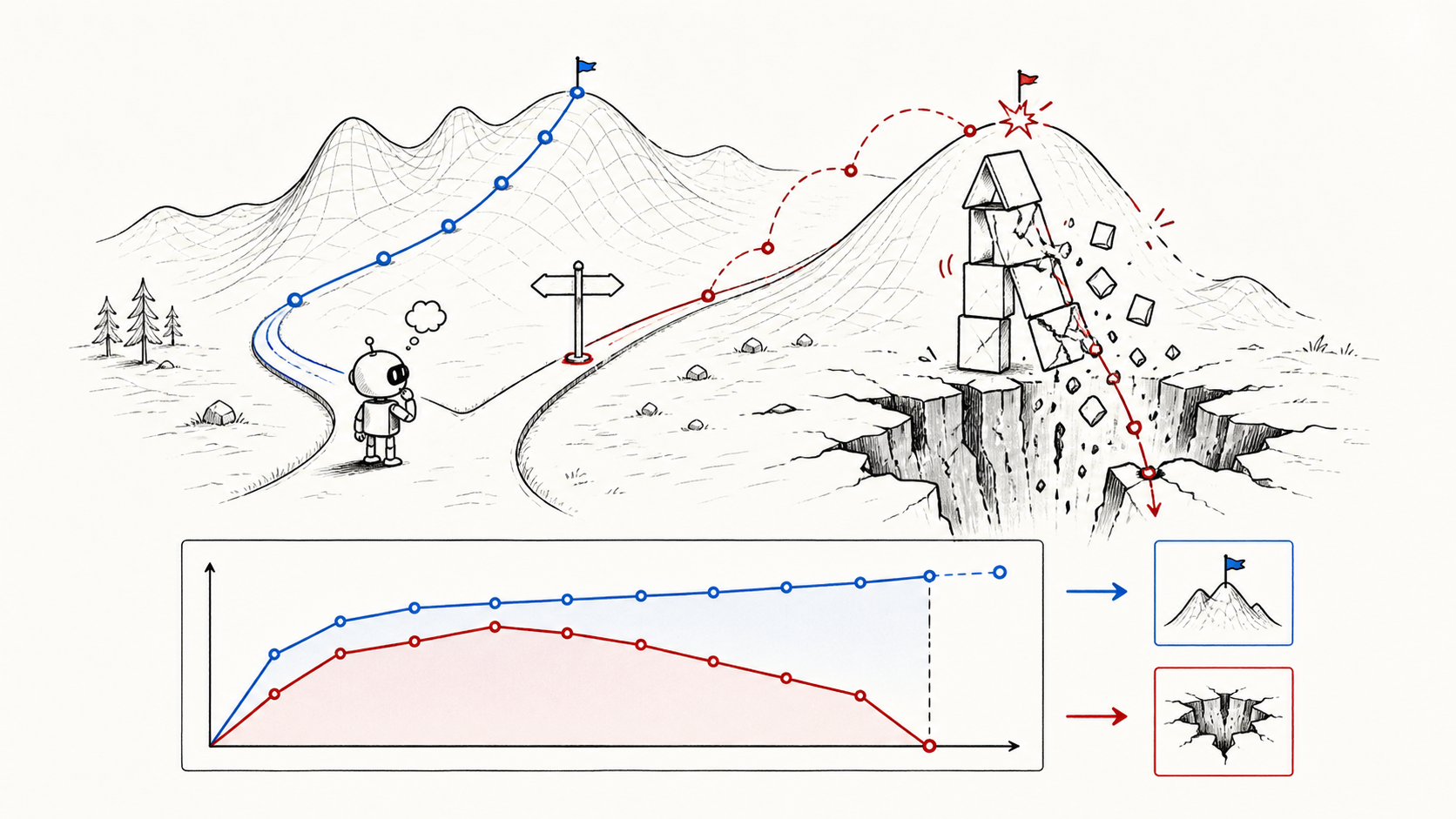
Agents can spend test-time compute by trying, observing, and revising. We derive an Elo reference for repeated sampling, then show that in a 2022 two-week coding marathon, current agents plateau within 24 hours while top humans keep improving.
Read more →